背景
binder很复杂!
很多讲解binder的书籍和资料,一上来就从引用计数说起,然后就开始讲 servicemanager 和 addService 的实现,具体逻辑里还要跟多线程、binder对象的生命周期、死亡通知、缓冲区管理逻辑等等反复纠缠,确实讲得很细致,但对于初学者来说,太过细致反而不利于抓住重点,往往看了上百页的书和几千行代码后,还是一头雾水。
那binder的核心中的核心是什么呢?
我个人觉得是 mmap 和 binder通信协议 ,只要彻底理解了这两点,就不会犯迷糊。而其他精妙的引用计数、缓冲区管理、生命周期管理都是在这两点的基础上为了达成效率更高、资源占用更少、系统更健壮的目的而存在的,是对binder大厦的“精装修”。在精装修之前,我们需要先关注binder的大框架。
多数基于Android源码做分析的都很难(或者说没办法)做到只讲大框架,因为各种“精装修”的代码是和大框架揉在一起的,很难无视其存在。那怎样才能彻底抛弃这些“精装修”呢?很简单,我们自己盖一个毛坯房呗。
理查德·费曼的黑板上写着这么一句话—— “What I cannot create, I do not understand ”,一语道破了 know 和 understand 的区别。虽没必要重新发明轮子,但亲手造一个轮子的过程以及其间波折,会让我们彻底理解轮子的工作原理。
那好,我们这就开始自己动手写一个binder!
1 代码
github 地址如下:
https://github.com/rightsubtree/minibinder
这些代码源自我在某个前东家时搞的一次内部培训,整体上基于Android kernel 4.19版本,大约对应于Android 9~10前后。最近整理电脑重新发现了它,感觉自己写得还不错,就厚着脸皮拿出来跟大家分享一下了。其中驱动层代码大约800行,应用层client+server合计约400多行,相比原生binder的鸿篇巨著,几乎瘦身到极致了。
出于简化的目的,minibinder仅仅选择了原生binder最核心的流程和逻辑,而且是在64位Linux上编译和运行的,读者可以自行修改代码添加想要的功能,可以对照着日志逐行分析(本文接下来也正是对着日志讲解的),作者的期望是,读者可以通过这个minibinder在几个小时内搞懂binder的最基础也是最核心的知识。
代码仅在64位的Linux环境里测试过,基本用法见下面:
1.1 编译
清空: make clean
编译全部:make all
也可以选择单独编译:
仅编译内核模块:make minibinder
仅编译客户端: make client
仅编译服务端: make server
1.2 添加和删除内核模块
添加并允许应用读写:
sudo insmod minibinder.ko && sudo chmod 777 /dev/minibinder
删除模块:
sudo rmmod minibinder
查看模块:
sudo lsmod | grep minibinder
如果修改了内核相关的代码后,需要重新 rmmod 和 insmod 方可生效;
删除模块时,如果提示ERROR: Module minibinder is in use,则需要关闭所有client和server进程后,再次执行一遍删除模块命令;
1.3 运行
在两个终端tab里分别执行 ./server 和 ./client
按照client的提示,选择和输入,查看运行结果;
client端显示效果:
server端显示效果:
1.4 日志
client 和 server的日志直接打在屏幕上;
内核日志请使用命令 dmesg 命令查看(建议开始测试前,用 sudo dmesg -c 命令先清空历史记录)
在目录 minibinder/log-and-comments/ 内提供了一份笔者测试时的日志 dmesg.txt 和 dmesg–with-comments.txt
本例的kernel内容很少,只有108行,我个人建议大家使用有颜色标记功能的工具(例如Notepad-- )查看,醒目且清晰:
为了方便理解,打日志这个环节我也略微做了一点儿工作,主要包括:
kernel日志的每一行开头都显示了当前进程的名字(binder_open时还打印了一下进程编号和线程编号),配上颜色标记后,就能清晰看到这一行日志运行在哪个进程里;
上一章节binder协议图里出现的BC_ BR_ BINDER_WORK_开头的cmd和work,都在日志中清晰体现;
重要的函数和处理流程的首尾,都添加了BEGIN和END,还用花括号括起来(花括号还是对齐的^_^),部分文本编辑器支持花括号的匹配显示,这样就能清晰看到流程头尾在哪里了;【例如日志中第28行和46行的对应】
对于重要的数据结构,例如 binder_buffer、 binder_transaction、 binder_transaction_data 等都将其核心信息打了出来,数据结构使用全名,其后用括号括起来重要信息;【例如,binder代码里,buffer这个词至少有两个含义,有时候指的是 binder_buffer 结构体,有时候指的是 binder_alloc结构体的 void __user *buffer 这个成员;binder_transaction既可以是一个结构体,也可以是一个函数,所以打印函数时后面添加了一个空的括号;所有这些刻意区别,都是为了避免混淆,尽量让代码和日志都最大程度易读】
涉及到有方向的cmd/work传递,都用箭头指明了目的进程;
希望这些努力能对大家有帮助。
2 mmap
2.1 黄金交割问题
在说mmap之前,我们先假设一个特殊场景:
假设你是一个经营实体黄金存储和转账业务银行(类似美联储,或者山西票号,whatever)的老板,A家要给B家付黄金,那么最保险的做法就是通过银行交割,把黄金从A家在银行的储藏间搬到B家在银行的储藏间。我们假设客户完全信任银行,允许银行直接从自己的储物间提取黄金,但客户只能打开属于自己的储物间。银行为了记账合规,规定黄金转运的两头不能都是客户的储藏间,至少有一头得是银行本身的金库。那怎么转运呢?
最直接的这样做(图中红色实线+黑色虚线,表示银行能完全访问客户的存储间,但客户不能访问银行的存储间。画法借用了马路上的分道线的含义 ^_^):
这种方案能工作,但总感觉挪动两次有些费劲,直到有一天,天才的你设计出了双门的储藏间,一个门朝内通往银行金库,一个门朝外允许客户提取黄金,两个门中间有一把锁,平常是锁闭状态,只有在需要让客户提取黄金前才打开(下图中体现为“洪-庚”之间默认的红色实线变成了绿色虚线),提取后立即关闭。那么转运就变得简单了:
希望这个假想的黄金交割问题能帮助大家理解,而不是增加大家的困扰。其实第二种方案中“双门的存储套间”,跟binder里面用到的mmap的逻辑是相似的。binder之所以能实现“一次IPC只拷贝一次数据”,最根本的还是因为其充分利用了mmap这一神兵利器。
2.2 函数原型、参数和返回值
mmap是Linux系统的一个IO函数,其设计初衷是为了方便读写文件,即将文件的一段内容直接映射到程序的虚拟内存空间,然后应用程序就可以通过更高效的指针操作用读写内存的方式实现读写文件。操作系统会自动将虚拟内存中的“脏数据”回写到文件,从而使得应用程序在不调用read/write等系统调用的情况下读写文件。
函数原型
1
2
3
#include <sys/mman.h>
void * mmap ( void * addr , size_t len , int prot , int flags , int fd , off_t off );
参数
void *addr : 指定映射区域的起始地址。通常设为 NULL,由内核自动选择合适地址;
size_t len : 映射区域的长度,单位是字节;
int prot : 指定内存保护方式,可以是以下值的组合:
PROT_READ: 可读。 PROT_WRITE: 可写。 PROT_EXEC: 可执行。 PROT_NONE: 不可访问。 int flags : 控制映射的类型和行为,常用选项包括:
MAP_SHARED: 共享映射,修改会写回文件。 MAP_PRIVATE: 私有映射,修改不会写回文件。 MAP_ANONYMOUS: 匿名映射,不与文件关联。 MAP_FIXED: 使用指定的起始地址,若不可用则失败。 int fd : 文件描述符,指定要映射的文件。匿名映射时设为 -1;
off_t off : 文件映射的偏移量,如果没有特别需求一般设置为 0;
返回值
2.3 内存映射区分布
下面这个图来自《Unix环境高级编程》,图中的len、off就是函数原型中的参数;
从图中我们可以看出来, 按照地址从低到高的顺序,Linux 进程的虚拟地址空间大致可以分为以下几个区域:
代码区(Text Segment):存放程序的执行代码。
数据区(Data Segment):存放程序的已初始化全局变量和静态变量。
BSS区(BSS Segment):存放未初始化的全局变量和静态变量。
堆区(Heap):动态分配内存(比如通过 malloc 或 new),生长方向从低到高;
栈区(Stack):存放函数调用的栈帧和局部变量,生长方向从高到低;
而内存映射区(Memory-mapped Region)一般位于堆区和栈区之间,生长方向从低到高;
在32位Linux系统,应用程序的虚拟地址空间是0x 0000 0000 ~ 0x bfff ffff(每个进程都有一份,各自独立),内核虚拟地址空间是0x c000 0000 ~ 0x ffff ffff(整个系统只有一份);
在64位Linux系统,应用程序的虚拟地址空间是0x 0000 0000 0000 0000 ~ 0x 0000 7fff ffff ffff(每个进程都有一份,各自独立),内核虚拟地址空间是0x ffff 8000 0000 0000 ~ 0x ffff ffff ffff ffff(同样是整个系统只有一份);
具体到每一个进程的各个区域分区,可以让进程打印自己的 /proc/self/maps 文件查看,下面是minibinder的client端打印的一组数据:
maps文件的每一列的含义依次是:address、perms、offset、dev、inode、pathname
从图中可以看出来,client端打开了 /dev/minibinder 这个文件,同时其内存映射区的范围是7fae812f3000-7fae812fd000,共计40K,范围也确实在应用程序的虚拟地址范围内;【另外,可以看出上面截图里stack和heap的位置,与《Unix环境高级编程》图中给的分布也是一致的】
第二列权限显示为 r--p,意思是可读、不可写、不可执行、私有,这与client 调用mmap时的参数 PROT_READ 和 MAP_PRIVATE 是对应的,详见代码 user_public.c 里的函数 binder_open :
1
2
3
4
5
6
struct binder_state * binder_open ( const char * driver , size_t mapsize ) {
struct binder_state * bs ;
//省略一些代码
bs -> mapped = mmap ( NULL , mapsize , PROT_READ , MAP_PRIVATE , bs -> fd , 0 );
//省略一些代码
2.4 mmap在binder的使用细节
截至目前,我们提到mmap时一直在说的是“方便读写文件”,都是面向文件的;
而按照Linux里一切皆文件 的哲学,binder里映射的文件实际上是一个驱动文件节点,而这个“驱动”实际上并不关联一个具体的硬件设备,而是关注与内核里一段内存的读写。那么应用程序用mmap映射驱动节点文件,本质上是将内核里的一段内存映射到了应用程序的虚拟地址空间;
所以,前面所述的“方便读写文件”,进一步变成了“方便程序读写内核里的一段内存”(按照上面参数PROT_READ的定义,准确地说是读内核里的一段内存,写内核内存需要内核用copy_from_user来实现);
“应用程序调用mmap映射驱动文件” + “驱动文件关注一段内核内存页面” 二者综合起来的效果就是,同一段内存,实际上有两个地址:从应用程序的视角看,它读的是用户空间虚拟地址;从内核的角度看,自己写的是内核空间的虚拟地址;
那么binder实现“一次IPC只拷贝一次数据”的核心思想就是:
从数据发送方提供的userspace地址,直接一次性拷贝到数据接收方可读的一个内存物理页面 ,然后告诉接受方该物理页面对应的userspace地址,接收方直接读数据。
大家可以结合上面转运黄金的第二种方案的图来理解上面这句话。另外,mmap内存与直接mmap普通文件的一个显著差异是,既然是读写内存,那就必然涉及到内存的分配和回收 (对应于上面黄金转运例子里的“腾空丙字间”和“回收丙字间”),这一点稍后会逐渐展开。
3 binder通信协议
接下来将会结合用户态和内核态的切换,简单讲一下binder通信协议。
相信很多读者会犯嘀咕:通信协议跟用户态和内核态的切换有啥关系呢?
还真有关系,了解了用户态和内核态的切换,结合这个切换过程,才能真正理解binder通信协议每一步是怎么触发的,以及协议为什么要这样设计。且听我慢慢分解。
3.1 用户态和内核态
涉及到驱动或者内核的时,经常见到用户态(user mode)和内核态(kernel mode)这两个词,这两者的区分是在操作系统层面进行的,这两种状态是操作系统为了安全和管理而设计的。
用户态和内核态如何相互切换?
内核态和用户态的切换主要通过中断 和系统调用 来实现。
当用户态的进程需要执行内核态的代码时,通常会通过系统调用 陷入到内核态。这个过程涉及到保存用户态的上下文 (如栈信息)到内核态,然后加载新的内核态的上下文开始执行。当内核态的代码执行完毕后,它会将控制权返回给用户态,并恢复原来的上下文,完成从用户态到内核态的切换。
同样,当一个中断 发生时,处理器会自动切换到内核态 ,执行相应的中断处理程序,处理完毕后再返回到用户态。整个切换过程涉及到处理器状态的保存和恢复,以及上下文的切换,需要操作系统的底层支持。
用户态和内核态切换时,进程会变化么?
不会。如上面所述,变化的是进程运行的上下文(主要是栈信息);
而内核是所有进程的管理者,也就是说不存在所谓的“内核进程”。一个进程既可以运行在用户态,也可以通过系统调用陷入内核态,进入内核态后,只是可以执行的功能增加了(当然操作系统不会允许其胡来,所有保护措施一直在工作),进程并没有变化。
确认其进程并没有变化的一个依据是,进入内核态后,依然可以访问用户态里所有的虚拟内存地址(前面讲mmap时提到了,用户虚拟地址是每个进程独立一份,内核地址空间整个系统唯一);假设内核态无法访问用户态的虚拟内存,那么copy_from_user 等函数就没有存在的意义了;
Binder流程中存在哪些用户态和内核态的切换?
Binder不涉及中断,所以Binder里的用户态和内核态的切换,都是由系统调用触发的。主要包括这些:
上述函数执行完毕后,都会从内核态返回用户态;
3.2 协议流程
如果我们从网上找binder通信协议的文档,一般能看到类似这样的图示(来自 http://gityuan.com 在此向这位大牛致敬):
这个图足够清晰,但从这个图里无法看出来 BINDER_WORK_TRANSACTION 的传递过程,所以我把整个过程画的稍微详细了一点:
上面图里,深蓝+浅蓝表示client进程,深红+浅红表示server进程,浅色都位于kernel中,代表进程陷入了内核态;可以发现,我将binder拆成了两部分,分别是client进程中的binder和server进程中的binder;为什么这样拆开呢?因为 从进程的角度看,并不存在“binder进程”这样的东西,binder的代码逻辑是并发地跑在client进程和server进程中的(更准确地说,是跑在client进程和server进程各自的内核态); 稍后我们逐行查看日志时,就能更加印证这一点;
从图中可以看出来这些信息:
client通过 BC_TRANSACTION 命令将请求数据即 binder_transaction_data 给到binder后,binder会将其转换成两个work,其中一个work的类型是 BINDER_WORK_TRANSACTION ,会给到server进程,另一个的work的类型是 BINDER_WORK_TRANSACTION_COMPLETE ,会返回给client;BINDER_WORK_TRANSACTION_COMPLETE的作用有两个:一是让发送者确信数据已经送达,二是可以让发送者线程休眠或者回到用户态继续做别的事儿。 server进程的binder逻辑在取得BINDER_WORK_TRANSACTION类型的work后,会用命令 BR_TRANSACTION 将请求给到server,server端开始执行业务逻辑; 业务逻辑处理完毕后,server端用 BC_REPLY 命令将reply数据(也是binder_transaction_data类型)写给驱动;BC_REPLY 命令的处理逻辑与 BC_TRANSACTION 类似,只是方向不同; server执行完毕业务逻辑后(意味着来自client的数据已经不需要了),在BC_REPLY前,通常会给驱动写一个 BC_FREE_BUFFER 命令,让驱动释放刚才存储BC_TRANSACTION命令的binder_transaction_data 的缓冲区; BR_REPLY被client接受处理完毕后,也会给驱动写一个BC_FREE_BUFFER 命令,让驱动释放刚才存储BC_REPLY命令的binder_transaction_data 的缓冲区;BC_ 开头的,是从用户空间到内核空间 的,即每一个BC_XXX 命令都伴随着进程通过ioctl写 的方式触发的一次用户态到内核态的切换(当然,ioctl写的调用栈执行完毕后会返回用户态);各种work的流转 不涉及用户态和内核态切换,都是在内核态完成的;这些“流转”是通过向目标 binder_proc的todo 列表添加work来实现的; BR_ 开头的,是内核空间到用户空间 的,即每一个BR_XXX 命令都伴随着进程通过ioctl读 的方式触发的一次用户态到内核态的切换(读到work项,则相关调用栈执行完毕后返回用户态;读不到数据,立刻返回用户态)【所谓的“读”,实际上是摘取“work流转”环节被添加到自己binder_proc的todo 列表的work项】;【我图中标记的序号和gityuan的图标记的略有不同,其实这个并没有什么影响。binder往对端进程todo队列里添加 BINDER_WORK_TRANSACTION 和往自己进程todo队列里添加 BINDER_WORK_TRANSACTION_COMPLETE 这两件事几乎是同时执行的,二者的处理也是两个进程并发做的,我这里是把真正干活transaction的放在了transaction_complete类型的前面。】
4 主要数据结构
先来看看本例中用到的一些binder的数据结构吧
原生binder的数据结构很多,本例子仅仅用到了这些。原生binder里被本例抛掉的主要有这些:
引用计数相关的: binder_node 、 binder_ref 、binder_ref_data 、binder_ref_death
调度和优先级相关的: binder_priority
binder传输对象相关的: binder_object binder_object_header flat_binder_object binder_fd_object binder_buffer_object binder_fd_array_object
本例子也没有考虑到多线程,但为了尽可能保持跟原生代码的接口一致, binder_thread 结构被大幅删减了;
图中数据类型有红色 标记的,表示将数据结构类型做了简化,例如 binder_alloc 结构的 buffers 本来是红黑树,我这里简化为一个list表示;pages 本来是 binder_lru_page 类型的(binder_lru_page里面包含了一个 page结构体指针),我直接去掉了中间的 binder_lru_page 类型,恢复成了旧版本binder里的 page指针的数组,即page的二级指针;binder_proc里面本来用红黑树类型的 threads 保存了当前进程的所有线程,由于我不考虑多线程,所以将其简化为 binder_thread 指针类型的 main_thread;
图中蓝色 标记的(主要是两个name域),是本例子为了打日志时能直接打印出来进程名称而添加的。
这些本例新增和修改的域,在代码里面也是有详细注释的。所有这些改动主要是为了能用最少的代码覆盖binder核心流程的逻辑。
好了,下面结合图,我们简单描述一下出场的各个数据结构,以及各自之间的关系:
binder_transaction_data
用于描述一次binder通信中的事务数据,跟 BC_TRANSACTION 或 BC_REPLY 的处理流程相关,其内容主要包括:
target:原生binder里表示通信目标binder对象;BC_TRANSACTION 场景,是一个 _u32类型;BR_TRANSACTION时,是一个binder_uintptr_t 类型的指针;本例里省略了这个域;
code:事务代码,更通俗地说就是要调用第几个功能;
flags:事务的标志位,一般用于事务数据携带 binder_object 类型等的情况(例如添加service到servicemanager时),本例暂时没有用到这个功能;
data_size:数据缓冲区的大小;
offsets_size:偏移量缓冲区的大小;
data.ptr.buffer:指向数据缓冲区的指针;
data.ptr.offsets:指向偏移量缓冲区的指针;
由于binder事务需要完成的功能各异,所以其数据数量、长度必然各异,那binder_transaction_data 怎样兼容这些差异呢?
首先,总长度我们肯定能算出来,那就用一个足够长的(64位系统直接用了_u64)data_size 域存一下;
其次,虽然需要携带的数据个数不同,但总能先申请一段长度等于data_size的内存data.ptr.buffer,将他们都依次拼接到buffer指向的区域吧?
然后又有新问题了,使用者怎样将data.ptr.buffer指向的data_size长度的数据砍断切成需要的N个数据呢?答案就是,我们把“在哪里砍开”这样的信息也存一下,对了,就是所谓的每个数据的offset,考虑到数据个数N不确定,那存储所有offset的区域也必须动态分配,用一个data.ptr.offsets指向之;可以将data.ptr.offsets理解为一个N元素的数组,每个数组都是一个binder_uintptr_t类型,即_u64,每个元素的值表示的是对应数据的偏移值,其实就是在它之前的所有元素的长度和 ;
当然,这个offsets指针指向的区域有多大,也需要知道,所以也得将offsets_size保存一下,而且在每个offset占用的长度固定(offset实际上就是内存地址的差值,所以64位系统每个offset都是一个_u64),那根据offsets_size的长度我们也能很容易知道数据总个数N是几;
遇事不决画个图,以本例附带的测试和日志用的数据为例,执行字符串替换操作,client提供了3个数据,分别是“Hello World”、“World”、“Binder”,那么此时binder_transaction_data 里面大体上是这样的布局:
一共三个数据,每个数据的offset都是一个_u64,所以 offsets 一共占了 8 * 3 = 24个字节;offsets[0]表示第一个数据“Hello World”在buffer中的偏移值,显然第一个数据的偏移值永远是0;offsets[1]表示“World”在buffer中的偏移值,实际上就是它之前的“Hello World”的长度,即11;同理offset[2]表示“Binder”在buffer中的偏移量,等于前面两个数据的总长度,即16;
binder_buffer
如上所述,binder_buffer 里面主要存储事务的数据强相关的内容,主要是 data_size、offsets_size、data.ptr.buffer、data.ptr.offsets 这几项所对应的数据;
data_size 和 offsets_size 会原样复制过来,而data.ptr.buffer 和 data.ptr.offsets 会被“序列化”到一段连续内存里,由指针 void __user *user_data 指向这段内存;将来数据接收者也会从这段内存里取得数据,并根据 data_size 的大小将内存分割成 buffer 和 offsets两部分;
同时,binder_buffer 持有一个其所属 binder_transaction 的指针;
vm_area_struct
vm_area_struct 是 Linux 内核中用于管理进程虚拟内存区域的关键数据结构。每个进程的虚拟地址空间由多个 vm_area_struct 实例描述,每个实例对应一个连续的虚拟内存区域。这些区域可以是代码段、数据段、堆、栈或内存映射文件等。binder里vm_area_struct 就是对应于一个内存映射文件;
一个binder进程最大 能使用多少 binder_buffer 空间,取决于vm_area_struct的大小,而vm_area_struct的大小又取决于执行mmap时的参数len;
那是否执行完毕mmap后,进程就能立即使用这么多的空间了么?并不是。类比一下上面黄金转运的例子,收款方租用了宇宙洪荒四个存储间,并不意味着现在这四个存储间都能用于接收付款方的黄金,因为只有银行(即驱动)给收款方腾出来宇宙洪荒(即进程的vm_area_struct)对应的一个“银行内部存储间”(分配一页内存),并且打开了客户存储区和银行内部存储区的锁(相当于将某一页内存和vm_area_struct关联起来,用的方法是vm_insert_page)后,收款方对应的存储区才能取货。
来个图简单描述一下 vm_area_struct、binder_buffer、page以及binder_alloc 中的几个关键变量的关系;
先看看原生binder里的情况:
vm_area_struct (简称vma)的大小就是进程所能使用的所有内存映射的容量总和,为了更加经济、动态的使用这些有限的容量,需要将vma按需分割,每个小块儿就是一个 binder_buffer,每个binder_buffer都有一个非常重要的user_data指针指向其对应的userspace地址(也就是说,user_data指向的地址是用户空间的虚拟地址),每个user_data指针都在vma的范围内;
然后为了真正存储数据,就需要给这些binder_buffer分配物理内存并记录分配结果;kernel出于速度考虑,通常是整页的换入换出的,所以就需要有 binder_alloc->pages 来记录所有已经分配的内存页【从图上可以看出,存在多个binder_buffer共享一个page的情况,也存在一个超长binder_buffer跨越多页的情况,这都加剧了binder_buffer管理的复杂性】
为了计算某个binder_buffer 在哪一页上,就需要binder_alloc 持有一个永恒不变的“基础地址”指针,这个指针就是 binder_alloc->buffer,永远指向vma->vm_start;(可见binder_alloc->buffer也是用户空间虚拟地址)
总之,vm_area_struct 是用户空间的一段虚拟地址空间,binder_buffer是这段虚拟地址空间的逻辑分割,page是对应于vma和binder_buffers的实体物理内存,binder_alloc 负责记录管理所有的分配/回收等;
为了简化,本例里将每个binder_buffer的大小都固定为一个page的大小,所以对应关系是这样的:
简化后,每个user_data 都等于 vma->vm_start + N * PAGE_SIZE,查找页序号、分配和释放物理页等的逻辑都很简单了;
5 流程详解
这里先放一幅核心流程的图示,方便大家对照。
这个图体现了 open和mmap、BC_TRANSACTION、BR_TRANSACTION、BC_FREE_BUFFER的主要流程(这几个协议就是我所谓的“流程前半段”,后续主要对前半段进行详细解释,后半段其实跟前半段逻辑类似,只是方向不同);
5.1 open和mmap
先从client和server端main函数第一行调用 user_public.c 里的函数 binder_open 函数(本例里有两个同名的binder_open函数,这个在应用层)开始:
1
2
int main ( int argc , char * argv []) {
struct binder_state * bs = binder_open ( DRIVER , MMAP_LENGTH );
应用程序里binder_open的具体内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct binder_state * binder_open ( const char * driver , size_t mapsize ) {
struct binder_state * bs ;
bs = malloc ( sizeof ( * bs ));
// 省略异常处理
bs -> fd = open ( driver , O_RDWR | O_CLOEXEC );
// 省略异常处理
bs -> mapsize = mapsize ;
bs -> mapped = mmap ( NULL , mapsize , PROT_READ , MAP_PRIVATE , bs -> fd , 0 );
// 省略异常处理
return bs ;
//省略一些异常处理的goto
}
这段代码比较简单,需要理解的主要是,open 和 mmap走到了哪里?
见 binder.c 的 第421行前后,定义 /dev/minibinder 为 misc 设备时,指定了其 open 、 mmap、 unlocked_ioctl 对应于哪些操作,这些是 Linux 设备驱动的默认写法,这里不多涉及了(因为我也只懂这些,嘿嘿)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
static struct file_operations dev_fops = {
. owner = THIS_MODULE ,
. open = binder_open ,
. mmap = binder_mmap ,
. unlocked_ioctl = binder_ioctl ,
};
static struct miscdevice misc = {
. minor = MISC_DYNAMIC_MINOR ,
. name = DEVICE_NAME ,
. fops = & dev_fops ,
};
static int __init dev_init ( void ) {
int ret ;
ret = misc_register ( & misc );
return ret ;
}
static void __exit dev_exit ( void ) {
misc_deregister ( & misc );
}
module_init ( dev_init );
module_exit ( dev_exit );
MODULE_LICENSE ( "GPL" );
MODULE_AUTHOR ( "rightsubtree@hotmail.com" );
也就是说,bs->fd = open(driver, O_RDWR | O_CLOEXEC); 会走到 binder.c 里302行这段代码里:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
static int binder_open ( struct inode * nodp , struct file * filp ) {
printk ( KERN_DEBUG "%s(%d|%d): binder_open \n " , current -> comm , current -> tgid , current -> pid );
struct binder_proc * proc ;
proc = kzalloc ( sizeof ( * proc ), GFP_KERNEL );
if ( proc == NULL ) return - 100 ;
filp -> private_data = proc ;
INIT_LIST_HEAD ( & proc -> todo ); // 初始化todo列表,后续的待处理的"work"都添加到这里
proc -> pid = current -> group_leader -> pid ;
proc -> alloc . pid = current -> group_leader -> pid ;
INIT_LIST_HEAD ( & proc -> alloc . buffers ); // 本例子里用list来管理所有的 binder_buffer 对象,先初始化之
// 这里直接记录一下两个proc信息,方便后续找到target_proc,亦即,让驱动本身起到了类似servicemanager的作用
if ( ! strncmp ( current -> comm , CLIENT_PROC_NAME , strlen ( CLIENT_PROC_NAME )) )
proc_client = proc ;
if ( ! strncmp ( current -> comm , SERVER_PROC_NAME , strlen ( SERVER_PROC_NAME )) )
proc_server = proc ;
// 保存进程名,打印日志时使用,主要用于打印对端进程名字时
memcpy ( proc -> name , current -> comm , strlen ( current -> comm ));
proc -> name [ strlen ( proc -> name )] = '\0' ;
return 0 ;
}
bs->mapped = mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0); 最终会走到 binder.c 里大约356行的这个函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
static int binder_mmap ( struct file * filp , struct vm_area_struct * vma ) {
printk ( KERN_DEBUG "%s(%d|%d): binder_mmap PAGE_SIZE=%ld \n " , current -> comm , current -> tgid , current -> pid , PAGE_SIZE );
int ret ;
struct binder_proc * proc = filp -> private_data ;
const char * failure_string ;
printk ( KERN_DEBUG "%s: %s: %d %lx-%lx (%ld K) vma=%llx \n " ,
current -> comm , __func__ , proc -> pid , vma -> vm_start , vma -> vm_end , ( vma -> vm_end - vma -> vm_start ) / SZ_1K , ( u64 ) vma );
// binder要求userspace不能写mmap的存储空间,否则报错,
// 也就意味着用户空间程序只能用 copy_from_user 和 copy_to_user 的方式与驱动进行数据传输
if ( vma -> vm_flags & FORBIDDEN_MMAP_FLAGS ) {
ret = - EPERM ;
failure_string = "bad vm_flags" ;
pr_err ( "%s: %d %lx-%lx %s failed %d \n " , __func__ , proc -> pid , vma -> vm_start , vma -> vm_end , failure_string , ret );
return ret ;
}
// VM_DONTCOPY:表示在 fork() 时,该虚拟内存区域(VMA)不会被复制到子进程中
// VM_MIXEDMAP:表示该虚拟内存区域是一个混合映射,可能包含多种类型的页面(如匿名页面和文件映射页面)
vma -> vm_flags |= VM_DONTCOPY | VM_MIXEDMAP ;
// 将 VM_MAYWRITE 标志从 vma->vm_flags 中清除,禁止该虚拟内存区域被动态修改为可写
vma -> vm_flags &= ~ VM_MAYWRITE ;
vma -> vm_ops = & binder_vm_ops ;
vma -> vm_private_data = proc ;
// 初始化当前binder_proc的binder_alloc,此乃记录每个binder_proc的buffer分配的一个结构体
return binder_alloc_mmap_handler ( & proc -> alloc , vma );
}
上面代码注释比较全。比较特别的是,binder对于vma->vm_flags的一系列处理,最终是为了确保用户空间进程只能读binder的内存,不能做写和拷贝;
binder_mmap的最后,走到了 下面函数 binder_alloc_mmap_handler函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
int binder_alloc_mmap_handler ( struct binder_alloc * alloc , struct vm_area_struct * vma ) {
int ret ;
const char * failure_string ;
int page_count = ( vma -> vm_end - vma -> vm_start ) / PAGE_SIZE ; // 用户空间的虚拟内存对应多少个内核页面空间
mutex_lock ( & binder_alloc_mmap_lock );
if ( alloc -> buffer ) {
ret = - EBUSY ;
failure_string = "already mapped" ;
goto err_already_mapped ;
}
// 永远指向mmap时vma的start位置,一旦mmap后就不变化了,后续会用alloc->buffer来计算相对页序号、页内偏移值等
alloc -> buffer = ( void __user * ) vma -> vm_start ;
mutex_unlock ( & binder_alloc_mmap_lock );
// binder_alloc的buffer_size表示当前binder_proc能使用的最大缓冲区空间,也是mmap后就固定了,等于mmap时指定的参数大小
alloc -> buffer_size = vma -> vm_end - vma -> vm_start ;
// 本例中没有用binder_lru_page结构体,pages是二级指针(相当于指针的数组的起始地址),其每个元素都是一个指向内核page的指针
alloc -> pages = kzalloc ( page_count * sizeof ( alloc -> pages [ 0 ]), GFP_KERNEL );
if ( alloc -> pages == NULL ) {
ret = - ENOMEM ;
failure_string = "alloc page array" ;
goto err_alloc_pages_failed ;
}
// 为vma虚拟内存创建对应的 binder_buffer ,需要注意的是,此时并没有给binder_buffer分配内核内存页面
// 为了简化,我们让每个binder_buffer的大小都正好是一个page,后续分配和释放,都以整个page为单位
// 所以 binder_alloc的域buffers这个列表也有 page_count 个元素,即 alloc->pages 和 alloc->buffers 的元素一一对应
for ( int i = 0 ; i < page_count ; i ++ ) {
struct binder_buffer * buffer = kzalloc ( sizeof ( * buffer ), GFP_KERNEL );
if ( ! buffer ) {
ret = - ENOMEM ;
failure_string = "alloc buffer struct" ;
goto err_alloc_buf_struct_failed ;
}
buffer -> user_data = alloc -> buffer + PAGE_SIZE * i ;
// 原生binder里面binder_alloc用红黑树管理buffers,这里简化为list
list_add_tail ( & buffer -> entry , & alloc -> buffers );
buffer -> free = 1 ;
}
// 打印一下看看,后面日志里可以跟这里的地址对照
// 包括 binder_buffer 本身地址,后面寻找空闲buffer时可对照,TNND,为了让大家搞明白,我真是操碎了心啊
struct binder_buffer * bb ;
int index = 0 ;
list_for_each_entry ( bb , & alloc -> buffers , entry ) {
printk ( KERN_DEBUG "%s: alloc->buffers <%d> binder_buffer(@ %llx user_data=%llx free=%d) \n " ,
current -> comm , index ++ , ( u64 ) bb , ( u64 ) bb -> user_data , bb -> free );
}
// 保存一个名字,主要是为了方便日志更易读
memcpy ( alloc -> name , current -> comm , strlen ( current -> comm ));
alloc -> name [ strlen ( alloc -> name )] = '\0' ;
binder_alloc_set_vma ( alloc , vma );
alloc -> vma_vm_mm = vma -> vm_mm ;
mmgrab ( alloc -> vma_vm_mm );
return 0 ;
//省略一些异常处理的goto
}
从这个函数,我们可以了解到这些:
vma的size 决定了binder能提供多少多少个物理pages关联到用户空间;
mmap操作只能执行一次;(但后续插入/移除物理页面是可以反复执行的,这两个要区别开)
binder_alloc的buffer域永远指向vma->vm_start,我们总是需要一个固定的起点来计算页面偏移的;
原生binder会在这个函数里面初始化binder_alloc的 buffers域(注意这里是复数buffers ),原生用的是红黑树来存储的;红黑树的好处是,能将历史使用过的buffer缓存下来,支持快速查找,从而能最大程度上避免反复做binder_buffer 的拆分和合并,毕竟一个server端提供的是一个有限的功能列表,其参数大抵也是相对固定的;原生binder一开始是拿出一半的空间初始化为第一个binder_buffer 的空间,后续会逐渐拆分/合并。本例为例简化,使用list存储binder_buffer,且直接将每个binder_buffer的大小固定了,kernel日志里打出来的正是这个list;
再次强调一下,此时vma对应了binder_buffer,但所有的binder_buffer都还没有分配物理页面;
走完驱动层的binder_open 和binder_mmap后,打出的日志如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
[ 133.489037] server(2539|2539): binder_open
[ 133.489048] server(2539|2539): binder_mmap PAGE_SIZE=4096
[ 133.489050] server: binder_mmap: 2539 7f64a7715000-7f64a771f000 (40 K) vma=ffff8caf647725f0
[ 133.489054] server: alloc->buffers <0> binder_buffer(@ ffff8cb30bcbb000 user_data=7f64a7715000 free=1)
[ 133.489056] server: alloc->buffers <1> binder_buffer(@ ffff8cb30bcbb8a0 user_data=7f64a7716000 free=1)
[ 133.489057] server: alloc->buffers <2> binder_buffer(@ ffff8cb30bcbbb40 user_data=7f64a7717000 free=1)
[ 133.489058] server: alloc->buffers <3> binder_buffer(@ ffff8cb30bcbb660 user_data=7f64a7718000 free=1)
[ 133.489059] server: alloc->buffers <4> binder_buffer(@ ffff8cb30bcbbc60 user_data=7f64a7719000 free=1)
[ 133.489060] server: alloc->buffers <5> binder_buffer(@ ffff8cb30bcbb7e0 user_data=7f64a771a000 free=1)
[ 133.489061] server: alloc->buffers <6> binder_buffer(@ ffff8cb30bcbba20 user_data=7f64a771b000 free=1)
[ 133.489062] server: alloc->buffers <7> binder_buffer(@ ffff8cb30bcbb6c0 user_data=7f64a771c000 free=1)
[ 133.489063] server: alloc->buffers <8> binder_buffer(@ ffff8cb30bcbb4e0 user_data=7f64a771d000 free=1)
[ 133.489064] server: alloc->buffers <9> binder_buffer(@ ffff8cb30bcbb480 user_data=7f64a771e000 free=1)
[ 137.748406] client(2541|2541): binder_open
[ 137.748415] client(2541|2541): binder_mmap PAGE_SIZE=4096
[ 137.748416] client: binder_mmap: 2541 7fae812f3000-7fae812fd000 (40 K) vma=ffff8caf6449a688
[ 137.748420] client: alloc->buffers <0> binder_buffer(@ ffff8caf446fd0c0 user_data=7fae812f3000 free=1)
[ 137.748422] client: alloc->buffers <1> binder_buffer(@ ffff8caf446fd960 user_data=7fae812f4000 free=1)
[ 137.748423] client: alloc->buffers <2> binder_buffer(@ ffff8caf446fdae0 user_data=7fae812f5000 free=1)
[ 137.748423] client: alloc->buffers <3> binder_buffer(@ ffff8caf446fd660 user_data=7fae812f6000 free=1)
[ 137.748424] client: alloc->buffers <4> binder_buffer(@ ffff8caf446fdc00 user_data=7fae812f7000 free=1)
[ 137.748425] client: alloc->buffers <5> binder_buffer(@ ffff8caf446fd900 user_data=7fae812f8000 free=1)
[ 137.748426] client: alloc->buffers <6> binder_buffer(@ ffff8caf446fd840 user_data=7fae812f9000 free=1)
[ 137.748426] client: alloc->buffers <7> binder_buffer(@ ffff8caf446fd720 user_data=7fae812fa000 free=1)
[ 137.748427] client: alloc->buffers <8> binder_buffer(@ ffff8caf446fd600 user_data=7fae812fb000 free=1)
[ 137.748428] client: alloc->buffers <9> binder_buffer(@ ffff8caf446fda20 user_data=7fae812fc000 free=1)
结合前面提到的,在64位Linux系统,应用程序的虚拟地址空间是0x 0000 0000 0000 0000 ~ 0x 0000 7fff ffff ffff,内核虚拟地址空间是0x ffff 8000 0000 0000 ~ 0x ffff ffff ffff ffff;
我们可以看出来,server端的vma的范围是 7f64a7715000-7f64a771f000,client端的vma的范围是 7fae812f3000-7fae812fd000,范围确实在用户虚拟地址空间,这个范围大小是40K,与我们执行mmap时的参数是一致的:
1
2
3
4
5
6
// user_public.h 中的定义:
#define DRIVER "/dev/minibinder"
#define MMAP_LENGTH (4096 * 10)
// client.c 和 server.c 中的调用:
struct binder_state * bs = binder_open ( DRIVER , MMAP_LENGTH );
server和client两个binder_proc 各自的 binder_alloc 的 buffers,都默认初始化了10个 binder_buffer,如前面所述,我们为了简化,将每个 binder_buffer的大小都固定成一页内存(4K)的大小,10个 binder_buffer正好对应于vma的40K空间;
我们以server端第一个 binder_buffer为例,binder_buffer(@ ffff8cb30bcbb000 user_data=7f64a7715000 free=1) ,其中ffff8cb30bcbb000 表示binder_buffer本身的地址,即处于内核虚拟地址范围内,因为这个对象本身是位于kernel内的,其user_data域等于7f64a7715000 ,这个7f64a7715000 正好就是server端vma的vm_start;【再次强调一下,本例里将binder_buffer的大小固定为4K,所以每个binder_buffer的user_data都对应于 vma->vm_start + N * 4096 的位置,N是其在buffers列表中的序号】
简单画一个图,描述一下当前的内存布局,希望有助于大家理解刚刚发生了什么。
配色和上面binder通信协议图中保持一致。深蓝和深红区域分别表示client和server的userspace的内存情况,浅蓝+浅红合起来是kernel的内存布局,其中浅蓝表示client进程的内核态,浅红表示server进程的内核态;
图中白色矩形表示一块儿内存,旁边如果有标签则表示其内存地址,内存地址数字与我提供的内核日志 dmesg.txt 中的数字保持一致;
这幅图主要表达了server和client两个binder_proc 各自的 binder_alloc 的 buffers ,都默认初始化了10个 binder_buffer且指向各自的vma,同时各自的 binder_alloc 的 pages 都还仅仅是空数组;后续内存里数据的变化都将基于这个基础展开;
5.2 BC_TRANSACTION
5.2.1 客户端ioctl写bwr,内核态拷bwr与btd
client是通信的发起方,通过调用 binder_write 函数, 将 BC_TRANSACTION + binder_transaction_data 组合信息发给驱动;
有一点需要说明,原生binder里,应用层是不知道binder_transaction_data这个结构体的,而是通过 IPCThreadState 类的域 Parcel mOut 封装了待发送的数据,Parcel 提供了一些列序列化/发序列化函数,以及数据的打包和解包函数。原生binder里Parcel 中的数据最终会被转换为 binder_transaction_data 中的 data.ptr.buffer 和 data.ptr.offsets,并在目标进程中重新解析为 Parcel 对象。因此,有些人会将 IPCThreadState 等类称为“IPC层”。本例为了简化,直接让client和server使用了binder_transaction_data结构体;
client 端准备数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
struct binder_transaction_data td ;
td . code = CODE_REPLACE_AND_REPLY ;
td . data_size = data_size ;
td . offsets_size = offsets_size ;
td . data . ptr . buffer = ( binder_uintptr_t ) buffer ;
td . data . ptr . offsets = ( binder_uintptr_t ) offsets ;
binder_size_t write_size = sizeof ( __u32 ) + sizeof ( struct binder_transaction_data );
__u32 * write_buffer = ( __u32 * ) malloc ( write_size );
* write_buffer = BC_TRANSACTION ;
memcpy ( write_buffer + 1 , & td , sizeof ( struct binder_transaction_data ));
binder_write ( bs , write_buffer , write_size );
binder_write 函数的内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int binder_write ( struct binder_state * bs , void * data , size_t len ) {
struct binder_write_read bwr ;
bwr . write_size = len ;
bwr . write_consumed = 0 ;
bwr . write_buffer = ( uintptr_t ) data ;
bwr . read_size = 0 ;
bwr . read_consumed = 0 ;
bwr . read_buffer = 0 ;
int res = ioctl ( bs -> fd , BINDER_WRITE_READ , & bwr );
if ( res < 0 ) {
fprintf ( stderr , "binder_write: ioctl failed (%s) \n " , strerror ( errno ));
}
return res ;
}
参考前面 /dev/minibinder 设备的定义,ioctl 函数最终会走到 binder.c 里面定义的函数 binder_ioctl:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static long binder_ioctl ( struct file * filp , unsigned int cmd , unsigned long arg ) {
int ret = 0 ;
struct binder_proc * proc = filp -> private_data ;
struct binder_thread * thread = binder_get_thread ( proc );
if ( thread == NULL ) {
return - 100 ;
}
switch ( cmd ) {
case BINDER_WRITE_READ :
ret = binder_ioctl_write_read ( filp , cmd , arg , thread );
if ( ret ) {
printk ( KERN_DEBUG "%s: ERROR binder_ioctl_write_read ret=%d \n " , current -> comm , ret );
}
break ;
default :
printk ( KERN_DEBUG "%s: binder_ioctl: currently do not support cmd=%d \n " , current -> comm , cmd );
ret = - EINVAL ;
}
return ret ;
}
binder_ioctl 会调用的函数 binder_get_thread 找到匹配的 binder_thread对象 ;原生binder这个函数是从 binder_proc 的以线程id来组织的红黑树threads里找到等于当前线程id的那个thread(即红黑树threads是一个能快速查找的线程池),本例将其简化为直接找到当前进程的主线程对应的 binder_thread对象;
因为cmd此时必然是 BINDER_WRITE_READ ,所以接着会走到binder_ioctl_write_read 函数,注意此时binder_ioctl_write_read 函数的第三个参数arg实际上来自于binder_ioctl 的最后一个参数,亦即binder_write 函数里面的 binder_write_read 结构体 bwr的地址,注意这个bwr是在用户空间的;
binder_ioctl_write_read 用 copy_from_user 的方式将 binder_write_read 结构体拷贝到kernel space;注意,这里拷贝的是 binder_write_read 结构体本身,即是浅拷贝,并没有沿着指针将所有关联数据都拷贝。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
static int binder_ioctl_write_read ( struct file * filp , unsigned int cmd ,
unsigned long arg , struct binder_thread * thread ) {
int ret = 0 ;
struct binder_proc * proc = filp -> private_data ;
void __user * ubuf = ( void __user * ) arg ;
struct binder_write_read bwr ;
if ( copy_from_user ( & bwr , ubuf , sizeof ( bwr ))) {
printk ( KERN_DEBUG "%s: binder_ioctl_write_read copy_from_user ERROR \n " , current -> comm );
ret = - EFAULT ;
}
if ( bwr . write_size > 0 ) {
ret = binder_thread_write ( proc , thread , bwr . write_buffer , bwr . write_size , & bwr . write_consumed );
}
if ( bwr . read_size > 0 ) {
// 最后一个参数中 O_NONBLOCK 表示非阻塞的方式,即没有数据可读时,立即返回
ret = binder_thread_read ( proc , thread , bwr . read_buffer , bwr . read_size , & bwr . read_consumed ,
filp -> f_flags & O_NONBLOCK );
}
return ret ;
}
然后,根据binder_write_read 的意图是要执行写还是读,来继续走到 binder_thread_write 或 binder_thread_read;
当前满足 bwr.write_size 大于零,所以会走到 binder_thread_write 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
static int binder_thread_write ( struct binder_proc * proc , struct binder_thread * thread ,
binder_uintptr_t write_buffer , size_t size , binder_size_t * consumed ) {
uint32_t cmd ;
void __user * buffer = ( void __user * )( uintptr_t ) write_buffer ;
void __user * ptr = buffer + * consumed ;
void __user * end = buffer + size ;
// 外层的while循环,是为了处理一个write写两个cmd的情况,
// 例如server通过一个ioctl写了一个包含 BC_FREE_BUFFER+ BC_REPLY的两个数据
while ( ptr < end ) {
if ( get_user ( cmd , ( uint32_t __user * ) ptr )) {
printk ( KERN_DEBUG "%s: binder_thread_write get_user ERROR \n " , current -> comm );
return - 1 ;
}
ptr += sizeof ( uint32_t );
switch ( cmd ) {
case BC_FREE_BUFFER : {
// 这里省略很多行代码
break ;
}
case BC_TRANSACTION :
case BC_REPLY : {
char * cmd_str = cmd == BC_TRANSACTION ? "BC_TRANSACTION" : "BC_REPLY" ;
printk ( KERN_DEBUG "%s: binder_thread_write cmd=%s BEGIN { \n " , current -> comm , cmd_str );
struct binder_transaction_data td ;
if ( copy_from_user ( & td , ptr , sizeof ( td ))) return - EFAULT ;
ptr += sizeof ( td );
binder_transaction ( proc , thread , & td , cmd == BC_REPLY );
printk ( KERN_DEBUG "%s: binder_thread_write cmd=%s END } \n " , current -> comm , cmd_str );
break ;
}
}
* consumed = ptr - buffer ;
}
return 0 ;
}
可以看到,对于 BC_TRANSACTION 和 BC_REPLY,处理逻辑是类似的,都是用 copy_from_user 的方式将 write_buffer 中的 binder_transaction_data 拷贝到内核空间里;
这次copy完毕binder_transaction_data后,内存布局大致如下图:
【实线箭头表示指针指向,其他表示拷贝或者插入关系的箭头会明确标注;虚线框表示拷贝后的结构体/内存;下同,不再赘述】
kernel里绿色的binder_write_read 结构体,是新拷贝来的,注意其write_buffer依然指向client的userspace的内存;橙色的binder_transaction_data是新拷贝来的,同样,此时其buffer和offsets依然指向client的userspace的内存;
5.2.2 创binder_transaction事无巨细,找binder_buffer有容奶大乃大
copy完毕binder_transaction_data后,继续执行 binder_transaction() 函数,这个函数相对长一些(有78行,嘿嘿),我们先看前一半:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
static void binder_transaction ( struct binder_proc * proc , struct binder_thread * thread ,
struct binder_transaction_data * td , int reply ) {
printk ( KERN_DEBUG "%s: binder_transaction() BEGIN { \n " , current -> comm );
char * cmd_str = reply ? "BC_REPLY" : "BC_TRANSACTION" ;
struct binder_transaction * t ;
struct binder_work * tcomplete ;
// 用最简单的方法找到目标进程
struct binder_proc * target_proc = ( proc == proc_client ? proc_server : proc_client );
printk ( KERN_DEBUG
"%s --> %s %s data.ptr.buffer=%llx data.ptr.offsets=%llx data_size=%lld offsets_size=%lld \n " ,
current -> comm , target_proc -> name , cmd_str , ( u64 ) td -> data . ptr . buffer , ( u64 ) td -> data . ptr . offsets ,
( u64 ) td -> data_size , ( u64 ) td -> offsets_size );
t = kzalloc ( sizeof ( * t ), GFP_KERNEL );
tcomplete = kzalloc ( sizeof ( * tcomplete ), GFP_KERNEL );
// 用发起者(即通过ioctl向内核写入数据的进程)提供的 binder_transaction_data 数据,构造一个 binder_transaction
t -> to_proc = target_proc ;
t -> from = thread ;
t -> code = td -> code ;
// 给binder_transaction分配一个 binder_buffer
// 这里binder_alloc_new_buf返回的binder_buffer已经是关联了一页内核page的
t -> buffer = binder_alloc_new_buf ( & target_proc -> alloc , td -> data_size , td -> offsets_size , current -> tgid );
if ( NULL == t -> buffer ) {
pr_err ( "%s: binder_alloc_new_buf cannot find free binder_buffer \n " , current -> comm );
return ;
}
t -> buffer -> transaction = t ;
t -> buffer -> data_size = td -> data_size ;
t -> buffer -> offsets_size = td -> offsets_size ;
// 如果正在处理BC_TRANSACTION,则填充其buffer的target_node,
// 后续会根据target_node是否为空决定下一个cmd是BR_TRANSACTION还是BR_REPLY;
// 这里的逻辑保持与原生binder一致,但target_node的数据类型有差异,详见 binder_buffer 结构体定义里的注释
if ( ! reply ) {
t -> buffer -> target_node = target_proc ;
}
//省略后一半
第1步,找到了 target_proc ,显然应该等于server进程的binder_proc对象;本例里只有client和server两个进程,所以做了很多简化;原生binder里面略微复杂,是通过binder_transaction_data的target.handle查询的。我们专注核心流程即可。
binder_transaction() 函数最核心的功能便是将来自发送者的数据拷贝到接受者的userspace里,所以这个target_proc 就是至关重要的,接下来将会通过 target_proc 的 binder_alloc 对象来分配 binder_buffer 和对应的物理内存 page,并将分配的物理内存page插入到target_proc 的vma里边,然后target_proc 的userspace【即server进程的业务逻辑】就能读取这个数据了;类比此前我们给出的黄金交割的例子,如果接收方找错了,后面做的再好也无济于事。
第2步,用我们获得的binder_transaction_data 构造一个 binder_transaction 对象,参考前面“主要数据结构”一节提到的,事务强相关的 数据会保存在 binder_transaction 对象里,而与待传输数据强相关 的内容则会保存到 binder_buffer 结构体对象中;而 binder_buffer 结构体对象的分配(包括为其关联物理内存页)就是此刻必须做了,这是由 binder_alloc_new_buf 函数完成的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// 从alloc->buffers列表中,找到一个空闲buffer,并将这个buffer与一页物理内存以及用户空间虚拟地址关联起来
struct binder_buffer * binder_alloc_new_buf ( struct binder_alloc * alloc , size_t data_size , size_t offsets_size , int pid ) {
struct binder_buffer * buffer ;
// 从alloc的buffers列表中找一个空闲的出来使用,单线程环境下,找到的buffer应该是vma的start,
// 然后调用binder_update_page_range时,相当于让vma->start关联到内核分配出的新的一个page的内存
list_for_each_entry ( buffer , & alloc -> buffers , entry ) {
printk ( KERN_DEBUG "%s: binder_alloc_new_buf list_for_each_entry binder_buffer(@ %llx user_data=%llx free=%d) \n " ,
current -> comm , ( u64 ) buffer , ( u64 ) buffer -> user_data , buffer -> free );
if ( buffer -> free ) {
printk ( KERN_DEBUG "%s: binder_alloc_new_buf: GOT free buffer \n " , current -> comm );
binder_update_page_range ( alloc , 1 ,
( void __user * ) PAGE_ALIGN (( uintptr_t ) buffer -> user_data ),
( void __user * ) PAGE_ALIGN (( uintptr_t ) buffer -> user_data + PAGE_SIZE ));
buffer -> data_size = data_size ;
buffer -> offsets_size = offsets_size ;
buffer -> pid = pid ; // 标记已经被某个进程占用
buffer -> free = 0 ; // 标记一下已经占用
return buffer ;
}
}
// 走完了list_for_each_entry,说明没有找到合适的
return NULL ;
}
找符合条件的binder_buffer的过程,原生binder也相对复杂,需要在红黑树找到一个大小合适的(红黑树是按照binder_buffer的大小组织的,能够快速查找,这应该是binder选择红黑树的原因吧),然后如果没有合适的还要涉及到binder_buffer 的拆分与合并。我们是用一个list来保存所有binder_buffer的,并且每个binder_buffer的大小都固定是4096,所以,遍历一下找一个空闲的即可,很显然,单线程环境下肯定会找到list的第0个,对应的日志如下:
1
2
3
4
5
[ 219.316488] client: binder_thread_write cmd=BC_TRANSACTION BEGIN {
[ 219.316492] client: binder_transaction() BEGIN {
[ 219.316493] client --> server BC_TRANSACTION data.ptr.buffer=5569eb54e2f0 data.ptr.offsets=7ffe7a095210 data_size=22 offsets_size=24
[ 219.316496] client: binder_alloc_new_buf list_for_each_entry binder_buffer(@ ffff8cb30bcbb000 user_data=7f64a7715000 free=1)
[ 219.316497] client: binder_alloc_new_buf: GOT free buffer
观察上面日志的开头即可知道,此时运行在client的内核态(当前还处于client的ioctl写 的调用栈内),注意我们找到的 binder_buffer(@ ffff8cb30bcbb000 user_data=7f64a7715000 free=1) ,观察其user_data的地址可以知道,这个其实就是 server进程执行 mmap时的 vma->vm_start,即此时我们检索的是server进程的buffers列表;
这就是上面查找 target_proc 的意义所在:既然将来是要把数据传输给server进程,那我就直接在server进程的buffers列表里找满足条件的 binder_buffer ,将来server进程就能直接取用这些地址的数据了。
此时内存布局如下图所示:
刚才我们创建了binder_transaction 结构体存储事务数据,并从target_proc 里找到一个大小足够的空闲的 binder_buffer 结构体对象,并使此binder_buffer和刚构造的binder_transaction互相关联;(浅红色区域,即server进程内核态的数据 proc->alloc->buffers 列表的第0个元素;绿色双箭头表示binder_buffer和binder_transaction互相持有对方地址)
5.2.3 alloc_page明修栈道,vm_insert_page暗度陈仓
binder_alloc_new_buf 函数继续往下走,就到了 binder_update_page_range 函数,这个函数有两个作用:
原生逻辑里,允许start和end地址任意,且可以跨越内存页,start到end的长度可以超过一页内存,所以整体逻辑就比较复杂,我们这里做了最大程度的简化,规定start必须是整页的起点(对应于上面说的,binder_buffer 都必须是整页大小4096),即 binder_buffer 和 物理PAGE 一一对应;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
// 原生binder的这个函数逻辑比较复杂,原因是要处理各种情况,包括但不限于:
// binder_buffer跨内存页、binder_buffer大小小于内存页、binder_buffer起始地址与内存页不对齐、
// 分配/释放 binder_buffer 时是否需要分配/释放内存页 等等;
// 本例子里简化为仅仅分配或者释放一页内存(亦即参数end实际没有使用),所以要求参数start是一个pagesize的起点
static int binder_update_page_range ( struct binder_alloc * alloc , int allocate ,
void __user * start , void __user * end ) {
printk ( KERN_DEBUG "%s: binder_update_page_range: allocate=%d start=%llx end=%llx \n " ,
current -> comm , allocate , ( u64 ) start , ( u64 ) end );
void __user * page_addr = start ;
struct vm_area_struct * vma = alloc -> vma ;
size_t index = ( page_addr - alloc -> buffer ) / PAGE_SIZE ;
if ( end <= start ) {
printk ( KERN_DEBUG "%s: binder_update_page_range ERROR: end <= start \n " , current -> comm );
return 0 ;
}
printk ( KERN_DEBUG "%s: %s(%d) %s pages for userspace %llx--%llx \n " ,
current -> comm , alloc -> name , alloc -> pid , allocate ? "allocate" : "free" , ( u64 ) start , ( u64 ) end );
// 分配一页
if ( allocate == 1 ) {
// 获得一个page
// 注意,这里 alloc_page 函数返回的是一个物理页面的地址,并不是虚拟地址,不能直接执行读写操作;
// 执行读写前,需要用 kmap 做映射,参考本文件内的函数 binder_alloc_copy_user_to_buffer 的做法;
struct page * page_ptr = alloc_page ( GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO );
if ( ! page_ptr ) {
pr_err ( "%d: binder_update_page_range failed alloc_page at %pK \n " , alloc -> pid , page_addr );
return 0 ;
}
alloc -> pages [ index ] = page_ptr ; // 记录到alloc的列表内,便于后续释放内存时检索
printk ( KERN_DEBUG "%s: allocate: alloc->pages[%ld] <--> kernel page_ptr=%llx <--> userspace page_addr=%llx \n " ,
current -> comm , index , ( u64 ) page_ptr , ( u64 ) page_addr );
// 将page_ptr指向的一页内核内存空间和用户空间的 page_addr 关联起来,
// 此后,用户空间就可以从 page_addr 读取到 page_ptr 所在页内存的数据
if ( vm_insert_page ( vma , ( unsigned long ) page_addr , page_ptr )) {
pr_err ( "%d: binder_update_page_range failed to map page at %llx in userspace \n " , alloc -> pid , ( u64 ) page_addr );
__free_page ( page_ptr ); // 避免内核page泄露
return 0 ;
}
printk ( KERN_DEBUG "%s: vm_insert_page(%llx, %llx, %llx) \n " , current -> comm , ( u64 ) vma , ( u64 ) page_addr , ( u64 ) page_ptr );
return 0 ;
}
// 释放一页
else {
// 省略
}
}
本例的 binder_update_page_range 函数,一上来先保存了一份目标进程的vma,然后计算了一下当前的 page_addr 对应于 alloc->pages 中的哪一页【可以再回头看一下 binder_alloc_mmap_handler 函数初始化 alloc->pages的逻辑 】;因为此时我们找到的 binder_buffer 的 user_data=7f64a7715000 ,即正好是 server的vma->vm_start ,而server进程的 alloc->buffer 也是初始化为 server的vma->vm_start 的【同样见 binder_alloc_mmap_handler 函数】,所以 size_t index = (page_addr - alloc->buffer) / PAGE_SIZE; 的计算结果必然是0,即刚才通过遍历buffers列表找到了第0个 binder_buffer,现在确认了其对应于server进程的vma的第0页;【注意,截至现在,还没有给vma分配任何物理内存页】
然后我们的参数allocate == 1,所以进入分配一页物理内存的逻辑,用 alloc_page 函数分配了一页物理内存,注意,这里获得是内核范围内的一页内存,alloc_page 返回的 page_ptr 是一个物理地址,还不能直接做读写用;
既然已经分配了一页内存,那么我们就可以更新alloc->pages[index]的值了;
类比此前的黄金交割的例子,我们现在相当于完成了“腾空丙字间”这一步;【丙字间位于银行内部存储区域,对应于这里的一页物理内存】,接下来要做的是,“打通洪-丙之间的通道”;在Linux上,这一步由 vm_insert_page 完成;
vm_insert_page 的函数原型为:
1
int vm_insert_page ( struct vm_area_struct * vma , unsigned long addr , struct page * page );
参数vma:指向目标虚拟内存区域(VMA)的指针。VMA 是进程虚拟地址空间中的一个连续区域,具有相同的权限和属性。这里可以简单理解为vma就是 static int binder_mmap(struct file *filp, struct vm_area_struct *vma) 函数的第二个参数;
参数addr:表示用户空间虚拟地址,表示页面插入的位置。该地址必须在 vma 的范围内;
参数page:指向要插入的物理页面的 struct page 指针。该页面通常由内核分配;
执行成功则返回0,失败则返回错误码;
代码运行到这里时,我们给出的vma是server进程的vma,addr是vma->vm_start,page是刚刚分配的内存的物理地址,所以效果是将刚刚分配的内存页插入到server进程的vma的起始位置;
回顾一下前面讲到binder_alloc_mmap_handler函数时,我们强调了 “vma对应了binder_buffer,但所有的binder_buffer都还没有分配物理页面” ,此时执行完毕 alloc_page 和 vm_insert_page 后,server进程的vma的第一页 (也就是下面图片里vma标记橙色的那一页)才算是真正可以执行读操作了(写操作依然是禁止的,是mmap时参数决定的),而没有插入物理内存页的vma地址范围依然不可读,否则会出现segment fault之类的错误;
完成了 vm_insert_page 后,我们又回到了 binder_transaction() 函数继续执行,接下来执行的是这几行:
1
2
3
4
5
6
7
t -> buffer -> transaction = t ;
t -> buffer -> data_size = td -> data_size ;
t -> buffer -> offsets_size = td -> offsets_size ;
if ( ! reply ) {
t -> buffer -> target_node = target_proc ;
}
给t->buffer即当前 binder_transaction 的 binder_buffer 赋值的这几行很简单;
在原生binder里, 对于BC_TRANSACTION,binder会将 t->buffer->target_node 设置为目标service的binder_node,用来标记当前是否出于binder流程的前半程(我这里称服务端执行业务逻辑之前为binder的前半程),如果是前半程,则后续的处理是把相关的work转换为BR_TRANSACTION,如果是后半程(服务端已经执行完毕业务逻辑,此刻binder_buffer服务于BC_REPLY),则相关的work应该转换成BR_REPLY;这样做的根本原因还是由于BC_TRANSACTION 和 BC_REPLY 的逻辑高度相似,总要有一个标志来区别二者。
此时内存布局如下图:
总结一下,相比上面一个图,我们刚刚又做了这些事情:
为binder_buffer对象分配一页物理内存;(kernel区域的橙色内存块儿,之所以画到client和server正中间,表示kernel里的物理内存是集中分配的,不会区别client还是server,后续可以看到这块儿内存又再次被client接收reply时用到了)
更新target_proc 的binder_alloc对象的物理页面记录 pages[index];(图中红色箭头)
将物理内存页插入target_proc 的VMA里,以便userspace通过vma范围内虚拟的地址访问此物理页面;(图中将server的vma的第一页内存也标记为橙色,蓝色箭头表示vm_insert_page后userspace的虚拟地址和kernel内的物理内存的对应关系。当前vma橙色一页可读,且读取的内容是kernel刚刚分配的那一页物理内存的内容)
这一段时间打出的日志如下:
1
2
3
4
[ 219.316498] client: binder_update_page_range: allocate=1 start=7f64a7715000 end=7f64a7716000
[ 219.316499] client: server(2539) allocate pages for userspace 7f64a7715000--7f64a7716000
[ 219.316502] client: allocate: alloc->pages[0] <--> kernel page_ptr=ffffd09244695c80 <--> userspace page_addr=7f64a7715000
[ 219.316504] client: vm_insert_page(ffff8caf647725f0, 7f64a7715000, ffffd09244695c80)
从每行日志的第一个进程名称也可以确定:
虽然我们遍历的是server进程的 binder_proc的 binder_alloc 里面的 buffers列表,更新的是是server进程的 binder_proc的 binder_alloc 里面的 pages地址数组,执行vm_insert_page时也是插入到server进程的vma的,但是,所有这一切其实都是由client进程在其内核态完成的 【别忘了,我们当前还在client进程的 ioctl写 的调用栈里面哦】;
5.2.4 百转千回data终拷贝,万事俱备work始派发
好了,到此我们刚刚讲完了binder_transaction() 函数的前一半,从上面图中可以发现,我们似乎一直在忙活很多“外围”的事情,需要传输的数据还没有动呢。这正是函数的后一半要做的;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// 接下来会执行两次 copy_from_user,将 binder_transaction_data 里面指针data.ptr.buffer和data.ptr.offsets指向的数据
// 拷贝到内核刚刚分配的 binder_buffer 里面;
// 本质上,这个拷贝实际上就是将原来 binder_transaction_data 里面的“结构化数据”做“序列化”的过程;
// 而到了对端进程(用户空间进程里),需要做“反序列化”,
// 反序列化时的解析规则是由 data_size 和 offsets_size 决定的,详见用户空间的 binder_parse 函数;
// binder_transaction_data 的 data.ptr.buffer 中存储了 data_size 个字节的数据,
// 将它们拷贝到刚刚分配的binder_buffer的第0个offset的位置;
if ( binder_alloc_copy_user_to_buffer ( & target_proc -> alloc , t -> buffer , 0 ,
( const void __user * )( uintptr_t ) td -> data . ptr . buffer , td -> data_size )) {
printk ( KERN_DEBUG "%d: got transaction with invalid data ptr \n " , proc -> pid );
}
// binder_transaction_data 的 data.ptr.offsets 其实是一个数组,存储了 offsets_size 个字节的数据
// (在64位系统,offsets_size = data.ptr.buffer里面obj的个数 * 8 ),
// 需要将它们拷贝到刚刚分配的binder_buffer的第 ALIGN(td->data_size, sizeof(void *)) 个offset的位置;
// ALIGN(x, y) 的意思是,将x上对齐到y的整数倍;假如 data_size=9,则64位上 ALIGN(9, 8) 计算后的值是16;
// ALIGN的主要目的还是为了加速数据读写速度
if ( binder_alloc_copy_user_to_buffer ( & target_proc -> alloc , t -> buffer , ALIGN ( td -> data_size , sizeof ( void * )),
( const void __user * )( uintptr_t ) td -> data . ptr . offsets , td -> offsets_size )) {
printk ( KERN_DEBUG "%d: got transaction with invalid offsets ptr \n " , proc -> pid );
}
// 将一个 BINDER_WORK_TRANSACTION 添加到 target_proc 的todo列表
// 所有添加到todo列表的都是一个 binder_work ,所以这里添加的其实是 binder_transaction 的一个子域 t->work 的指针
// 后续target_proc 执行到 binder_thread_read 收到binder_work后,通过 container_of 宏获得外层的 binder_transaction
t -> work . type = BINDER_WORK_TRANSACTION ;
list_add_tail ( & t -> work . entry , & target_proc -> todo );
printk ( KERN_DEBUG
"%s: --> %s BINDER_WORK_TRANSACTION (code=%d buffer=%llx data_size=%ld offsets_size=%ld) \n " ,
current -> comm , target_proc -> name , t -> code , ( u64 ) t -> buffer , t -> buffer -> data_size , t -> buffer -> offsets_size );
// 将一个 BINDER_WORK_TRANSACTION_COMPLETE 添加到源进程的todo列表,会被源进程在执行 binder_thread_read 时获取
tcomplete -> type = BINDER_WORK_TRANSACTION_COMPLETE ;
list_add_tail ( & tcomplete -> entry , & thread -> proc -> todo );
printk ( KERN_DEBUG "%s: --> %s BINDER_WORK_TRANSACTION_COMPLETE \n " , current -> comm , thread -> proc -> name );
printk ( KERN_DEBUG "%s: binder_transaction() END } \n " , current -> comm );
}
从上面代码中可以看出来,binder_transaction() 函数的后一半主要做了两件事儿:
拷贝buffer和offsets;
添加两个work项;
拷贝是通过 binder_alloc_copy_user_to_buffer() 函数完成的, 在分析其代码之前,我们先想一个问题,所有的拷贝,都需要知道to 、from 、size 这三个关键信息,那我们现在逐一核对一下:from很清晰,就是上面图片里client进程用户空间里 data.ptr.buffer 和data.ptr.offsets 的地址;size也很清楚,就是 data_size 加上 offsets_size;还剩下目的地to待确认,当然,在我们当前简化了之后的方案里,每个 binder_buffer 对应一个 page的物理内存,那么 binder_buffer 的 user_data必然是对应于这一个page物理内存的开头的,直接从这页物理内存开头写即可;
我们思考一下更一般的情况吧,我们需要:
从 binder_buffer 的 user_data计算出来其起始于alloc->pages中的第几页(index)的哪个偏移(pgoff);
由于需要拷贝的数据长度(bytes)不确定,那必然存在两种可能:
1、当前页的剩余空间足够放下数据(即pgoff + bytes < 4096); 2、当前页的剩余空间放不下数据(即pgoff + bytes > 4096),那就需要找到下一个page,然后将剩余数据写入; 如前面所述,alloc_page返回的是页面的物理地址,那么物理地址怎样转换成虚拟地址?
此刻可以回头看看 “主要数据结构” 一节最后的两个图,下面我们来继续分析:
先看第一次拷贝 data.ptr.buffer 的调用:
1
2
3
4
// binder_transaction_data 的 data.ptr.buffer 中存储了 data_size 个字节的数据,
// 将它们拷贝到刚刚分配的binder_buffer的第0个offset的位置;
if ( binder_alloc_copy_user_to_buffer ( & target_proc -> alloc , t -> buffer , 0 ,
( const void __user * )( uintptr_t ) td -> data . ptr . buffer , td -> data_size ))
binder_alloc_copy_user_to_buffer 函数如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
// 从参数 from 所指向的用户空间,拷贝 bytes 个字节内容,
// 到指定的 buffer + buffer_offset 的位置(这两个地址相加后,可能跨越了PAGE_SIZE);
unsigned long binder_alloc_copy_user_to_buffer ( struct binder_alloc * alloc , struct binder_buffer * buffer ,
binder_size_t buffer_offset , const void __user * from , size_t bytes ) {
while ( bytes ) {
unsigned long size ;
unsigned long ret ;
struct page * page ;
pgoff_t pgoff ;
void * kptr ;
void * kptr_page ;
// 获得页面物理地址
page = binder_alloc_get_page ( alloc , buffer , buffer_offset , & pgoff );
// min_t(type, x, y) 用于从type类型的两个数x和y中找到一个较小的
// 这个比较的意思是,如果需要copy的字节数bytes未达到本page的最后(即不跨页)则直接写bytes个;
// 如果跨页了,则先copy本页内剩余部分,后面的部分留到while循环的下一轮copy;
// 原生binder这样做,是为了能充分利用每一个字节的空间,做得还是很细致的,不服不行!
// 当然,本例子里肯定不存在跨页的情况;
size = min_t ( size_t , bytes , PAGE_SIZE - pgoff );
// kmap函数将物理页面映射到内核的虚拟地址空间中,返回一个虚拟地址,通过这个虚拟地址,内核可以访问物理内存;
// kmap()是与 kunmap()配对使用的;kmap()映射内存,kunmap()释放映射;
// kptr = kmap(page) + pgoff; // 本例子把原生的这行拆成下面两行,目标是为了打印出来kmap(page)的结果
kptr_page = kmap ( page );
kptr = kptr_page + pgoff ;
printk ( KERN_DEBUG "%s: binder_alloc_copy_user_to_buffer: kmap(%llx) got kernel virtual addr %llx \n " ,
current -> comm , ( u64 ) page , ( u64 ) kptr_page );
// 忙活了半天,终于可以做正儿八经的copy了
ret = copy_from_user ( kptr , from , size );
printk ( KERN_DEBUG "%s: binder_alloc_copy_user_to_buffer: copy_from_user(%llx, %llx, %ld) \n " ,
current -> comm , ( u64 ) kptr , ( u64 ) from , size );
// 释放本页映射
kunmap ( page );
// copy_from_user 的返回值是“未能成功复制的字节数”,
// 所以这里return的值含义是整体上剩余未copy的字节数;当然,一般走不到这里;
if ( ret ) return bytes - size + ret ;
bytes -= size ;
from += size ;
buffer_offset += size ;
}
return 0 ;
}
外围的while循环是为了处理一个binder_buffer 跨越物理页的情况。一进来,需要先调用函数 binder_alloc_get_page 找一下参数 buffer 对应的binder_buffer 对应于哪一页物理内存:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// 查询指定的 binder_buffer地址 + buffer_offset 偏移后(注意,二者相加后可能大于PAGE_SIZE), 对应的内核page物理地址,
// 物理地址数据来自当前进程的 binder_alloc 的 pages 的某个下标里,
// 这个 binder_alloc->pages[index] 是在 binder_alloc_free_buf --> binder_update_page_range 过程中设置的;
static struct page * binder_alloc_get_page ( struct binder_alloc * alloc , struct binder_buffer * buffer ,
binder_size_t buffer_offset , pgoff_t * pgoffp ) {
printk ( KERN_DEBUG "%s: binder_alloc_get_page: alloc->buffer=%llx binder_buffer(@ %llx user_data=%llx free=%d) buffer_offset=%llx \n " ,
current -> comm , ( u64 ) alloc -> buffer , ( u64 ) buffer , ( u64 ) buffer -> user_data , buffer -> free , ( u64 ) buffer_offset );
// alloc->buffer永远等于虚拟内存的vma->vm_start,而 buffer->user_data 是某个已经分配空间的 binder_buffer 的起始地址,
// (buffer->user_data - alloc->buffer) 就是某个 binder_buffer 相对vma_start的偏移,
// 再加上buffer_offset(即buffer内的offset),就是某个地址相对vma_start的偏移;
// 另外,这些参与计算的地址都是用户空间的虚拟地址
binder_size_t buffer_space_offset = buffer_offset + ( buffer -> user_data - alloc -> buffer );
// 求buffer_space_offset相对自己所在页的页首的偏移
pgoff_t pgoff = buffer_space_offset & ~ PAGE_MASK ;
// PAGE_SIZE=4k时,PAGE_SHIFT=12,所以 >> PAGE_SHIFT 相当于除以PAGE_SIZE,结果是获取相对页序号(编号从0开始)
size_t index = buffer_space_offset >> PAGE_SHIFT ; // 获取相对于vma->vm_start的页序号
printk ( KERN_DEBUG "%s: binder_alloc_get_page: index=%ld pgoff=%llx page=%llx \n " ,
current -> comm , index , ( u64 ) pgoff , ( u64 ) alloc -> pages [ index ]);
* pgoffp = pgoff ;
return alloc -> pages [ index ];
}
上述代码里的注释足够清楚了,这里不再细说了。需要稍微提一下的是 PAGE_MASK 和 PAGE_SHIFT 这两个宏定义;
宏定义PAGE_MASK 等于 ~(PAGE_SIZE-1) ,在PAGE_SIZE = 4096 (即2的12次方) 的情况下,其等于12个二进制位全0;宏定义 PAGE_SHIFT等于12;
所以 addr & ~PAGE_MASK 的结果相当于计算出addr在其所在页内的偏移量; addr >> PAGE_SHIFT 的结果相当于除以 PAGE_SIZE 后取整,即计算其相对页序号(从0开始);
回到上面的函数 binder_alloc_copy_user_to_buffer,获得binder_buffer所在的物理页的物理地址page后,接着做了这些:
通过一个简单的 min_t 比较判断一下当前页是否还有足够空间写下所有bytes个数据; 然后通过 kptr_page = kmap(page) 计算出来物理地址page对应的虚拟地址,然后添加pgoff获得最终的写入地址kptr(因为我们设置的每个user_data 地址都是物理页的头,所以第一拷贝data.ptr.buffer 时pgoff肯定是0); 紧接着通过 copy_from_user(kptr, from, size) 执行拷贝,注意此时的from是 (const void __user *)(uintptr_t)td->data.ptr.buffer 即是从client的用户空间拷贝的;其中 td 是从用户空间拷贝到kernel里的那个 binder_transaction_data,即binder_transaction() 函数的入参之一; 最后通过 kunmap(page) 这与刚才的kmap映射必须成对出现,不可以遗漏; 用binder_alloc_copy_user_to_buffer 拷贝 data.ptr.buffer过程的日志如下:
根据copy_from_user 时 from=5569eb54e2f0,也可以确认此时确实是从userspace拷贝的;
1
2
3
4
[ 219.316506] client: binder_alloc_get_page: alloc->buffer=7f64a7715000 binder_buffer(@ ffff8cb30bcbb000 user_data=7f64a7715000 free=0) buffer_offset=0
[ 219.316507] client: binder_alloc_get_page: index=0 pgoff=0 page=ffffd09244695c80
[ 219.316508] client: binder_alloc_copy_user_to_buffer: kmap(ffffd09244695c80) got kernel virtual addr ffff8caf5a572000
[ 219.316509] client: binder_alloc_copy_user_to_buffer: copy_from_user(ffff8caf5a572000, 5569eb54e2f0, 22)
第二次执行 binder_alloc_copy_user_to_buffer 拷贝 td->data.ptr.offsets 的调用如下:
1
2
3
4
5
6
7
8
9
// binder_transaction_data 的 data.ptr.offsets 其实是一个数组,存储了 offsets_size 个字节的数据
// (在64位系统,offsets_size = data.ptr.buffer里面obj的个数 * 8 ),
// 需要将它们拷贝到刚刚分配的binder_buffer的第 ALIGN(td->data_size, sizeof(void *)) 个offset的位置;
// ALIGN(x, y) 的意思是,将x上对齐到y的整数倍;假如 data_size=9,则64位上 ALIGN(9, 8) 计算后的值是16;
// ALIGN的主要目的还是为了加速数据读写速度
if ( binder_alloc_copy_user_to_buffer ( & target_proc -> alloc , t -> buffer , ALIGN ( td -> data_size , sizeof ( void * )),
( const void __user * )( uintptr_t ) td -> data . ptr . offsets , td -> offsets_size )) {
printk ( KERN_DEBUG "%d: got transaction with invalid offsets ptr \n " , proc -> pid );
}
基本过程跟上面第一次拷贝 data.ptr.buffer 时是类似的,只有一点区别,即这里的第三个参数 buffer_offset 是 ALIGN(td->data_size, sizeof(void *)),主要是为了对齐到8个字节,ALIGN的含义见上面注释;
这个过程中的日志如下:
1
2
3
4
[ 219.316510] client: binder_alloc_get_page: alloc->buffer=7f64a7715000 binder_buffer(@ ffff8cb30bcbb000 user_data=7f64a7715000 free=0) buffer_offset=18
[ 219.316511] client: binder_alloc_get_page: index=0 pgoff=18 page=ffffd09244695c80
[ 219.316512] client: binder_alloc_copy_user_to_buffer: kmap(ffffd09244695c80) got kernel virtual addr ffff8caf5a572000
[ 219.316513] client: binder_alloc_copy_user_to_buffer: copy_from_user(ffff8caf5a572018, 7ffe7a095210, 24)
两次拷贝完毕后,分配到的物理内存里的数据分布如下图示:
data_size=22,所以经过 ALIGN(22, 8) 之后得到的是24,即后面的offsets从24的位置开始,所以22和23两个位置有空洞;
经过两次拷贝后,当前内存中的布局如下:
图中从client的userspace到内核物理页面的两个红色箭头表示刚刚的两次copy_from_user,由于这一页物理内存映射到了server的vma的第一页,所以,此刻server从其vma->vm_start是可以读到刚刚两次拷贝的数据的;当然,我们需要告诉server进程,“来活了,你有数据要读哦”,这个告知功能是通过往server进程的 binder_proc->todo 列表里添加一个 work项实现的,也就是上面说的 binder_transaction() 函数的后半部要做的第二件事儿,添加两个work项:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// 将一个 BINDER_WORK_TRANSACTION 添加到 target_proc 的todo列表
// 所有添加到todo列表的都是一个 binder_work ,所以这里添加的其实是 binder_transaction 的一个子域 t->work 的指针
// 后续target_proc 执行到 binder_thread_read 收到binder_work后,通过 container_of 宏获得外层的 binder_transaction
t -> work . type = BINDER_WORK_TRANSACTION ;
list_add_tail ( & t -> work . entry , & target_proc -> todo );
printk ( KERN_DEBUG
"%s: --> %s BINDER_WORK_TRANSACTION (code=%d buffer=%llx data_size=%ld offsets_size=%ld) \n " ,
current -> comm , target_proc -> name , t -> code , ( u64 ) t -> buffer , t -> buffer -> data_size , t -> buffer -> offsets_size );
// 将一个 BINDER_WORK_TRANSACTION_COMPLETE 添加到源进程的todo列表,会被源进程在执行 binder_thread_read 时获取
tcomplete -> type = BINDER_WORK_TRANSACTION_COMPLETE ;
list_add_tail ( & tcomplete -> entry , & thread -> proc -> todo );
printk ( KERN_DEBUG "%s: --> %s BINDER_WORK_TRANSACTION_COMPLETE \n " , current -> comm , thread -> proc -> name );
printk ( KERN_DEBUG "%s: binder_transaction() END } \n " , current -> comm );
}
这段代码比较简单,就是往两个队列的尾部分别添加了一个work结构体,稍有区别的是,往源进程(当前是client 的binder_proc)里面添加的就是一个独立的binder_work结构体,且其type是BINDER_WORK_TRANSACTION_COMPLETE,意思是告诉源进程,“数据已经送达”;往target_proc (当前是server的 binder_proc )里面添加的work实际上是binder_transaction 类型的一个子域且其type是BINDER_WORK_TRANSACTION,这个work的处理将会是接下来server进程最重要的事儿;
也就是说,一方面binder要求todo队列里的元素必须都是 binder_work,而另一方面需要处理的工作项的类型多样、工作项需要的数据各不相同,怎么办呢?binder的处理是:既然没有办法创造出一个包罗万象的binder_work 结构体,那就让所有待处理数据都包含一个binder_work 结构体吧。 这有很强的Linux内核的味道,Linux内核里面list的逻辑也是一样的(所有期望能形成list的数据结构里,都请自行包含一个list节点,然后内核只维护list节点之间的prev和next关系)。
如代码中注释所言,后续target_proc 实际需要的不是binder_work结构体,而是binder_transaction结构体,所以target_proc执行到 binder_thread_read 收到binder_work后,需要通过 container_of 宏 获得外层的 binder_transaction(下一节会简单讲一下container_of 宏);
此刻内存布局大体如下图所示:
图中仅用两个红色箭头表示 todo list的链接关系,没有仔细画prev和next的双向链表关系;
添加work项的日志如下,添加完毕两个work后,binder_transaction()函数结束,调用binder_transaction()的 binder_thread_write函数也随之结束;
1
2
3
4
[ 219.316514] client: --> server BINDER_WORK_TRANSACTION (code=1 buffer=ffff8cb30bcbb000 data_size=22 offsets_size=24)
[ 219.316515] client: --> client BINDER_WORK_TRANSACTION_COMPLETE
[ 219.316515] client: binder_transaction() END }
[ 219.316516] client: binder_thread_write cmd=BC_TRANSACTION END }
类比此前那个黄金交割问题的话,相当于我们已经完成了下面6个步骤中的前3步;
为收款方创建双门的存储套间(mmap);
腾空“丙”字间(alloc_page),并打开“洪-丙”之间的通道(vm_insert_page);
从付款方的“地”字间运到银行内部金库“丙”字间 copy_from_user( kmap(page),from,size) ;
告知收款方从其“洪”字间取黄金;
收款方取完后,告知银行(BC_FREE_BUFFER);
银行关闭“洪-丙”之间的通道(zap_page_range),回收丙字间(__free_page);
终于把第一个binder命令BC_TRANSACTION 走完了,我们可以看出来,第一步BC_TRANSACTION处理完毕后,数据已经被拷贝到了 server 的vma里面,最复杂的工作已经完成了,可想而知,接下来server端获取数据的流程应当是相对简单的;
5.3 BR_TRANSACTION
5.3.1 container_of 按图索骥
前一个协议命令BC_TRANSACTION的处理流程最后,binder分别向 server和client 两个进程的 binder_proc 的 todo 队列里面各添加了一个work项。server端的type是 BINDER_WORK_TRANSACTION,这个需要server端实际干活的,我们先看看跟这个work有关的处理。
当client进程从用户态陷入内核态处理BC_TRANSACTION时,server进程并没有闲着,本例里我们是让它每200ms执行一次ioctl读,看看有没有“work”需要做:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main ( int argc , char * argv []) {
struct binder_state * bs = binder_open ( DRIVER , MMAP_LENGTH );
print_maps ();
binder_size_t read_size = sizeof ( __u32 ) + sizeof ( struct binder_transaction_data );
__u32 * read_buffer = ( __u32 * ) malloc ( read_size );
// 循环等待
while ( 1 ) {
// 休息200ms,否则可能导致进程长期占用CPU,作为一个演示程序,我们不关心进程的休眠唤醒等细节
usleep ( 200 );
// 先读一下看有没有驱动传递来的命令
binder_read ( bs , read_buffer , read_size ); // binder_read内部每次都会先将read_buffer置空
// 然后解析,没有读到也无所谓,对于空数据,binder_parse内部会啥也不干直接退出
binder_parse ( bs , read_buffer );
}
return 0 ;
}
ioctl读的动作见下面的 binder_read() 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// 通过ioctl从binder驱动读取长度len的数据,将读取到的内容写入data内
int binder_read ( struct binder_state * bs , void * data , size_t len ) {
memset ( data , 0 , len ); // data将来要存储新的数据,所以先清空一下,好习惯
struct binder_write_read bwr ;
bwr . write_size = 0 ;
bwr . write_consumed = 0 ;
bwr . write_buffer = 0 ;
bwr . read_size = len ;
bwr . read_consumed = 0 ;
bwr . read_buffer = ( uintptr_t ) data ;
int res = ioctl ( bs -> fd , BINDER_WRITE_READ , & bwr );
if ( res < 0 ) {
fprintf ( stderr , "binder_read: ioctl failed (%s) \n " , strerror ( errno ));
}
return res ;
}
ioctl读的结果将会保存到read_buffer,也就是 main函数里面malloc 出来的 长度等于 sizeof(__u32) + sizeof(struct binder_transaction_data) 的内存里;
如上所述,ioctl将会使 server进程进入内核态,继而执行 binder_ioctl()函数,因为ioctl的第二个参数cmd=BINDER_WRITE_READ,所以肯定继续走binder_ioctl_write_read()函数(函数binder_ioctl和binder_ioctl_write_read在前面第5.2.1节已经提过了,这里就不重复贴代码了);
因为我们给的read_size是 sizeof(__u32) + sizeof(struct binder_transaction_data) ,所以肯定会走到 binder_thread_read 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
static int binder_thread_read ( struct binder_proc * proc , struct binder_thread * thread ,
binder_uintptr_t read_buffer , size_t size , binder_size_t * consumed , int non_block ) {
void __user * buffer = ( void __user * )( uintptr_t ) read_buffer ;
void __user * ptr = buffer + * consumed ;
uint32_t cmd ;
struct binder_transaction_data td ;
struct binder_work * w ;
struct binder_transaction * t = NULL ;
if ( ! list_empty ( & proc -> todo )) {
// 获取binder_work结构体并,将list内该元素删除掉
w = binder_dequeue_work_head_ilocked ( & proc -> todo );
switch ( w -> type ) {
case BINDER_WORK_TRANSACTION : {
printk ( KERN_DEBUG "%s: binder_thread_read BINDER_WORK_TRANSACTION BEGIN { \n " , current -> comm );
// container_of 是linux里面一个很巧妙的宏定义,这里不多展开了
t = container_of ( w , struct binder_transaction , work );
printk ( KERN_DEBUG
"%s: binder_transaction(code=%d, data_size=%ld, offsets_size=%ld buffer->user_data=%llx) \n " ,
current -> comm , t -> code , t -> buffer -> data_size , t -> buffer -> offsets_size , ( u64 ) t -> buffer -> user_data );
// 如果是整个流程的前半程,则驱动将BR_TRANSACTION写给server端;如果是后半程,则驱动使用BR_REPLY将结果写给client端
cmd = t -> buffer -> target_node ? BR_TRANSACTION : BR_REPLY ;
char * cmd_str = ( cmd == BR_TRANSACTION ) ? "BR_TRANSACTION" : "BR_REPLY" ;
// 根据 binder_buffer 中的 userdata 重新构造出一个 binder_transaction_data;
td . code = t -> code ;
td . data_size = t -> buffer -> data_size ;
td . offsets_size = t -> buffer -> offsets_size ;
td . data . ptr . buffer = ( uintptr_t ) t -> buffer -> user_data ;
td . data . ptr . offsets = ( uintptr_t ) t -> buffer -> user_data + ALIGN ( t -> buffer -> data_size , sizeof ( void * ));
// 将 binder_transaction_data 写到binder_thread_read的入参指定的地址里,用户进程在 ioctl 执行完毕后就能用了
if ( put_user ( cmd , ( uint32_t __user * ) ptr )) return - EFAULT ;
ptr += sizeof ( uint32_t );
printk ( KERN_DEBUG "%s: put_user: cmd=%s \n " , current -> comm , cmd_str );
if ( copy_to_user ( ptr , & td , sizeof ( td ))) return - EFAULT ;
ptr += sizeof ( td );
printk ( KERN_DEBUG "%s: copy_to_user: binder_transaction_data "
"(code=%d data_size=%lld offsets_size=%lld data.ptr.buffer=%llx data.ptr.offsets=%llx) \n " ,
current -> comm , td . code , td . data_size , td . offsets_size , ( u64 ) td . data . ptr . buffer , ( u64 ) td . data . ptr . offsets );
printk ( KERN_DEBUG "%s: binder_thread_read BINDER_WORK_TRANSACTION END } \n " , current -> comm );
break ;
}
case BINDER_WORK_TRANSACTION_COMPLETE : {
// 省略
}
}
}
return 0 ;
}
binder_thread_read 函数关心的是当前 binder_proc 的 todo 列表,会依次从其头部取出来一个work处理(5.2.4节是尾部插入,现在是头部取用,确保先进先出的处理顺序),我们把第5.2.4节最后里的todo列表单独详细画一下:
当todo列表为空时:
假设某个todo列表有两个work,一个是BINDER_WORK_TRANSACTION,另一个是BINDER_WORK_TRANSACTION_COMPLETE,则其数据关系如下:
摘取work项的函数如下:
1
2
3
4
5
6
7
// 从list前端取出来一个元素,如果元素非空则将其从list删除掉;
static struct binder_work * binder_dequeue_work_head_ilocked ( struct list_head * list ) {
struct binder_work * w ;
w = list_first_entry_or_null ( list , struct binder_work , entry );
if ( w ) list_del_init ( & w -> entry );
return w ;
}
函数binder_dequeue_work_head_ilocked会从list里面摘取第一个非空的元素(即取出来并将其从list删除掉),这里的元素其实指的是包含 list_head 的结构体,即 binder_work 结构体;
关于Linux中 list_head 的用法,也挺有趣的,值得研究一下,这里就不展开了,要展开又得写一个长篇了。
如果binder_work的type是 BINDER_WORK_TRANSACTION,则接下来的 container_of(w, struct binder_transaction, work) 一句的意思是,通过指向内部名为work的这个域的指针w,找到指向外部结构体类型struct binder_transaction的指针 。binder_transaction 的定义如下:
1
2
3
4
5
6
7
8
9
10
struct binder_transaction {
struct binder_work work ;
struct binder_thread * from ;
struct binder_proc * to_proc ;
struct binder_thread * to_thread ;
unsigned need_reply ;
struct binder_buffer * buffer ;
unsigned int code ;
unsigned int flags ;
};
继续分析后续流程前,我们顺便了解一下 container_of 吧,其定义如下:
1
2
3
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member) *__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
这里面又涉及另一个宏 offsetof,其定义如下:
1
#define offsetof(type, member) ((size_t)&(((type *)0)->member))
我们先看看offsetof,这个宏的意思是计算type结构体的成员member相对于结构体的起始地址的偏移量。我们从内往外依次拆开看:
(type *)0:将 0 强制转换为指向 type 结构体的指针。这里的 0 是一个空指针(NULL),但它仅用于计算偏移量,不会实际访问内存。为什么使用0呢?主要是为了避免内存分配,特别是在被频繁调用的系统宏定义里分配内存和释放内存;((type *)0)->member:通过空指针访问 type 结构体中的 member 成员。由于 0 是空指针,这不会导致运行时错误,因为它只用于编译时的地址计算。&(((type *)0)->member):获取 member 的地址。由于结构体的起始地址是 0,member 的地址就是它的偏移量。(size_t):将偏移量转换为 size_t 类型,这是一个无符号整数类型,通常用于表示大小或偏移量。offsetof 的工作原理基于以下事实:
在 C 语言中,结构体的成员在内存中是连续存储的。
编译器在编译时知道每个成员的偏移量(由结构体的定义决定),或者可以说代码里对type->member的使用,编译时会自动转换成 type + offsetof(type, member) 的形式,既然是编译时,还没到运行时,那使用(type *)0就是没问题的;
通过将结构体的起始地址假设为 0,成员的地址就是它的偏移量。
再回到container_of宏,先看第一行:
1
const typeof ((( type * ) 0 ) -> member ) * __mptr = ( ptr );
typeof括起来的部分 ((type *)0)->member 刚才在offsetof时已经说过了,意思就是访问type结构体的member成员,然后外面加一个typeof,就是获取member的类型,所以container_of宏第一行的等号前面的代码起始就是定义了一个member类型的指针变量 __mptr,然后将第一个参数ptr 赋值给这个变量;
然后第二行代码:
1
( type * )(( char * ) __mptr - offsetof ( type , member ));
有了上面的offsetof的知识,这个就很清楚了,就是将第一行定义的指针__mptr 转换成 char* 类型,然后做指针的算数运算,减去member域相对type类型的偏移量,那自然就得到了member域的外层对象type的地址,最后不要忘了转换成type *类型,简单画个图如下;
看到这里,脑子转的快的同学可能会想到一个问题, 那第一行的赋值有啥用呢? 我直接对指向member域的指针ptr做减法不就行了么?是这么回事儿。但是,假如我给的入参指针ptr并不是指向member域的呢?比如,container_of(w, struct binder_transaction, work) 中,我用错了第一个参数,给的入参不是指向work域的,会发生什么?那岂不是随后的指针减法所得的结果必然出问题?所以,第一行的作用就显现出来了,第一行就是用来检查ptr的类型的!第一行赋值操作等号左边必然是一个指向member域的指针类型,等号右边是参数ptr,那如果指针类型不匹配,编译时就会报错。例如,我尝试将第一个参数w换成一个 char* 类型指针,编译时的报错:
总之,通过 container_of 我们能找到由client进程在其内核态时挂在 server进程的 binder_proc的todo列表上的 binder_transaction;
然后,简单几行赋值就完成了 binder_transaction_data 数据的构造:
1
2
3
4
5
td . code = t -> code ;
td . data_size = t -> buffer -> data_size ;
td . offsets_size = t -> buffer -> offsets_size ;
td . data . ptr . buffer = ( uintptr_t ) t -> buffer -> user_data ;
td . data . ptr . offsets = ( uintptr_t ) t -> buffer -> user_data + ALIGN ( t -> buffer -> data_size , sizeof ( void * ));
上面计算 offsets 时计算ALIGN跟 第5.2.4节里 binder_transaction() 函数里调用 binder_alloc_copy_user_to_buffer() 前计算ALIGN是对应的。
看到上面对td.data.ptr.buffer和td.data.ptr.offsets赋值操作,可能有些同学会有疑问: 就这么两句赋值就完了么? BC_TRANSACTION 阶段对内存的处理那么麻烦,这里就这么简单么?是的,就是这么简单。或者说,正是因为BC_TRANSACTION 阶段的麻烦才造就了此刻的简单。
根本原因还是在于 t->buffer->user_data 本身就是userspace的地址,更准确地说,是 binder_thread_read 所在进程的vma范围内的userspace地址(原因见调用函数 binder_alloc_copy_user_to_buffer() 时的第一个参数,用的是target_proc的alloc,自然会映射到target_proc的vma范围内),所以,上面对td.data.ptr.buffer 和 td.data.ptr.offsets的赋值是完全正确的,地址不需要做任何转换。后续回到用户态后拿到data.ptr.buffer和data.ptr.offsets也是可以直接读的;
也就是说,回头再看一下第5.2.4节里 binder_transaction() 函数里 binder_alloc_copy_user_to_buffer() 函数调用的 copy_from_user 不仅仅是从userspace拷贝到kernel,其实更准确地是 copy from source binder_proc userspace to target binder_proc userspace ,binder 利用 “mmap映射vma到内核” + “将 存储待传输数据的物理页面 直接映射到target_proc的vma” 这两项华丽操作,实现了 “一次IPC中数据只拷贝一次” 的终极目标;
窃以为,这里似乎还隐藏着这些思想:
此刻内存布局大致如下:
图中两条红色粗箭头表示经过上述赋值后,td.data.ptr.buffer和td.data.ptr.offsets已经自然指向到了前面找到的合适的binder_buffer对象的user_data所指向的内存地址,也就是binder_buffer对应的server端vma的一个区域(此vma区域已经通过vm_insert_page关联到了前面alloc_page分配到的物理内存页);
获取binder_transaction的日志只有这两行,可见确实是server端的内核态打出来的:
1
2
[ 219.316707] server: binder_thread_read BINDER_WORK_TRANSACTION BEGIN {
[ 219.316709] server: binder_transaction(code=1, data_size=22, offsets_size=24 buffer->user_data=7f64a7715000)
5.3.2 user_data 信手拈来
构造完毕 binder_transaction_data 后,接下来server进程的内核态所作的最后两件事儿就是:
1、用 put_user 将 cmd=BR_TRANSACTION 写到 ioctl读的read_buffer 的前4个字节里;
2、用copy_to_user的方式将 binder_transaction_data 拷贝到 ioctl读的read_buffer 后面的空间里;
1
2
3
4
5
if ( put_user ( cmd , ( uint32_t __user * ) ptr )) return - EFAULT ;
ptr += sizeof ( uint32_t );
printk ( KERN_DEBUG "%s: put_user: cmd=%s \n " , current -> comm , cmd_str );
if ( copy_to_user ( ptr , & td , sizeof ( td ))) return - EFAULT ;
然后 binder_thread_read 就执行完毕了;
这段时间的日志:
1
2
3
[ 219.316712] server: put_user: cmd=BR_TRANSACTION
[ 219.316713] server: copy_to_user: binder_transaction_data (code=1 data_size=22 offsets_size=24 data.ptr.buffer=7f64a7715000 data.ptr.offsets=7f64a7715018)
[ 219.316714] server: binder_thread_read BINDER_WORK_TRANSACTION END }
简单总结一下server通过ioctl读获取数据的过程:
通过查看自己的 binder_proc 的 todo 列表,确认“有没有活干?”;
通过binder_work的type,确定要干的是啥样的活,跟接收数据有关的type是 BINDER_WORK_TRANSACTION;
如果类型是BINDER_WORK_TRANSACTION,则需要用 container_of 的方式找到外部 binder_transaction,继而找到跟这个work有关的binder_buffer;binder_transaction结构体里面存储了跟事务本身相关的信息,binder_buffer的user_data 域指明了要去哪里取本事务的数据;
利用 binder_transaction 和 binder_buffer 里的信息,构造出一个 binder_transaction_data;
通过put_user和copy_to_user 的方式将 BR_TRANSACTION 和 binder_transaction_data 写入ioctl的read_buffer,这样ioctl返回后,server进程回到用户态,就能从read_buffer里获取binder_transaction_data了;【回过头来可以发现,收发两端能处理的,都是binder_transaction_data】
此刻的内存布局:
通过解析binder_transaction_data,server的用户空间就可以完整的获得所有信息了。
到现在为止,“传输一次数据”的工作已经完成了。
对着上面的图示,我们想问一个问题:整个通信过程中,有哪些数据拷贝?确实是“一次拷贝”么?
其实图中已经非常清晰地标记了所有出现的拷贝动作,按照时间顺序如下:
发送端执行ioctl写时,用 copy_from_user 将 binder_write_read 结构体拷贝到内核空间;
binder_thread_write函数,用 get_user 将cmd= BC_TRANSACTION 从发送端的用户空间拷贝到内核,然后用 copy_from_user 将 binder_transaction_data 拷贝到内核空间;
binder_transaction() 函数在alloc_page和vm_insert_page 完成后,用 copy_from_user 将来自发送端用户空间的 buffer 和 offsets 拷贝到刚刚分配的内存页里;
接收端执行ioctl读时,用 copy_from_user 将 binder_write_read 结构体拷贝到内核空间;
随后binder_thread_read函数,先用 put_user 将cmd=BR_TRANSACTION 从内核空间写入接收端的用户空间,然后用copy_to_user 将binder_transaction_data 拷贝到接收者的用户空间;
严格来说,确实不是“一次拷贝”,而是一共发生了五次 copy_from_user 或者 copy_to_user,其中第1和第4是ioctl过程中必要的 binder_write_read,第2和第5是拷贝的 cmd + binder_transaction_data 这样必备的事务数据,第3项拷贝是传递了真正的 payload 数据。binder_write_read、cmd、binder_transaction_data的大小是固定的,类似于“帧头/帧尾”,是任何协议化的通信中必不可少。 binder所谓的“一次拷贝”,指的是一次IPC通信中,payload数据仅仅被拷贝了一次。 (注意,reply已经是第二次IPC了哦)
server端用户空间收到数据后,需要执行“业务逻辑”,然后是reply,通常还需要告知binder释放接收数据过程的内存,这些对应于BC_REPLY 和 BC_FREE_BUFFER,我们稍后讲(见下面的函数 replace_and_reply )。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int binder_parse ( struct binder_state * bs , __u32 * ptr ) {
struct binder_transaction_data td ;
__u32 cmd = * ptr ;
// server端仅仅需要处理 BR_TRANSACTION 和 BR_TRANSACTION_COMPLETE
switch ( cmd ) {
case BR_TRANSACTION : {
printf ( "BR_TRANSACTION \n " );
memcpy ( & td , ++ ptr , sizeof ( struct binder_transaction_data ));
// 根据code决定服务端执行哪些功能
if ( CODE_REPLACE_AND_REPLY == td . code ) {
replace_and_reply ( bs , & td );
}
break ;
}
case BR_TRANSACTION_COMPLETE : {
printf ( "BR_TRANSACTION_COMPLETE \n " ); // 作为测试程序,这里啥也不需要做
break ;
}
}
return 0 ;
}
5.4 BR_TRANSACTION_COMPLETE
简单分析一下 BINDER_WORK_TRANSACTION_COMPLETE 这个work的处理;
client在第一个ioctl写将三个字符串写给binder后,就会进入循环ioctl读的过程,在本例里可能读取到的消息包括 BR_TRANSACTION_COMPLETE 以及 BR_REPLY;
client.c 里面循环ioctl读的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
binder_size_t read_size = sizeof ( __u32 ) + sizeof ( struct binder_transaction_data );
__u32 * read_buffer = ( __u32 * ) malloc ( read_size );
char result [ MAX_INPUT * 2 + 1 ];
memset ( result , 0 , MAX_INPUT * 2 + 1 );
// 循环等待,直到等到最后结果
while ( 1 ) {
// 休息200ms,否则可能导致进程长期占用CPU,作为一个演示程序,我们不关心进程的休眠唤醒等细节
usleep ( 200 );
// 先读一下看有没有驱动传递来的命令/回复
binder_read ( bs , read_buffer , read_size ); // binder_read内部每次都会先将read_buffer置空
// 解析
int status = 0xFF ;
binder_parse ( bs , read_buffer , & status , result );
// 解析成功
if ( status == 0 ) {
printf ( "success! result = %s \n \n " , result );
// 退出循环等待,重新回到用户选择功能
break ;
}
}
参考前面对server进程ioctl读的分析,整个流程还是一样的,依次调用 binder_ioctl() 、 binder_ioctl_write_read()、binder_thread_read() :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
static int binder_thread_read ( struct binder_proc * proc , struct binder_thread * thread ,
binder_uintptr_t read_buffer , size_t size , binder_size_t * consumed , int non_block ) {
void __user * buffer = ( void __user * )( uintptr_t ) read_buffer ;
void __user * ptr = buffer + * consumed ;
uint32_t cmd ;
struct binder_transaction_data td ;
struct binder_work * w ;
struct binder_transaction * t = NULL ;
if ( ! list_empty ( & proc -> todo )) {
// 获取binder_work结构体并,将list内该元素删除掉
w = binder_dequeue_work_head_ilocked ( & proc -> todo );
switch ( w -> type ) {
case BINDER_WORK_TRANSACTION : {
// 省略
break ;
}
case BINDER_WORK_TRANSACTION_COMPLETE : {
printk ( KERN_DEBUG "%s: binder_thread_read BINDER_WORK_TRANSACTION_COMPLETE BEGIN { \n " , current -> comm );
cmd = BR_TRANSACTION_COMPLETE ;
kfree ( w );
if ( put_user ( cmd , ( uint32_t __user * ) ptr )) return - EFAULT ;
printk ( KERN_DEBUG "%s: binder_thread_read put_user cmd=BR_TRANSACTION_COMPLETE \n " , current -> comm );
ptr += sizeof ( uint32_t );
printk ( KERN_DEBUG "%s: binder_thread_read BINDER_WORK_TRANSACTION_COMPLETE END } \n " , current -> comm );
break ;
}
}
}
return 0 ;
}
对BINDER_WORK_TRANSACTION_COMPLETE的处理很简单,直接将对应的 binder_work 结构体取下来后就地free掉(确实没有携带任何有价值数据),然后通过 put_user 的方式往用户空间写了一个cmd=BR_TRANSACTION_COMPLETE,内核态的事情就完毕了;
内核态的日志也很简单:
1
2
3
[ 219.316951] client: binder_thread_read BINDER_WORK_TRANSACTION_COMPLETE BEGIN {
[ 219.316952] client: binder_thread_read put_user cmd=BR_TRANSACTION_COMPLETE
[ 219.316953] client: binder_thread_read BINDER_WORK_TRANSACTION_COMPLETE END }
回到用户态后,原生binder里,对BR_TRANSACTION_COMPLETE还是要做一些特别处理的,例如线程调度之类的,我们这里一切从简,client端通过binder_parse函数解析,对于cmd=BR_TRANSACTION_COMPLETE,除了打印一行信息外不做特别处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int binder_parse ( struct binder_state * bs , __u32 * ptr , int * stauts , char * result ) {
struct binder_transaction_data td ;
__u32 cmd = * ptr ;
// client端仅仅需要处理 BR_TRANSACTION_COMPLETE 和 BR_REPLY
switch ( cmd ) {
case BR_TRANSACTION_COMPLETE : {
printf ( "BR_TRANSACTION_COMPLETE \n " ); // 作为测试程序,这里啥也不需要干
break ;
}
case BR_REPLY : {
// 省略
}
}
return 0 ;
}
后续在BC_REPLY协议处理完毕后,server端也会收到一个BR_TRANSACTION_COMPLETE(日志见下面),与我们刚刚分析过的client收到的逻辑是类似的,也同样很简单,所以后续在BC_REPLY后就不再重复了。
1
2
3
[ 219.317265] server: binder_thread_read BINDER_WORK_TRANSACTION_COMPLETE BEGIN {
[ 219.317266] server: binder_thread_read put_user cmd=BR_TRANSACTION_COMPLETE
[ 219.317267] server: binder_thread_read BINDER_WORK_TRANSACTION_COMPLETE END }
5.5 BC_FREE_BUFFER
本例中server端所谓的业务逻辑仅仅是做一下字符串替换,不赘述了。完成业务逻辑后,需要向client端返回结果。
考虑到数据传输(BC_TRANSACTION 以及后面的 BC_REPLY)过程中需要占据 binder_buffer 空间,那么找一个合理的时间释放binder_buffer 就是个必不可少的事儿。那何时释放最合理呢?理论上是接收端用完数据时,而这个“用完时”往往也就是执行完毕业务逻辑时。对于需要reply的事务,binder选择将释放binder_buffer 的命令和reply命令一起发送,且释放binder_buffer 的命令在前;
server端的用户态通过ioctl写的方式向binder写了BC_FREE_BUFFER + BC_REPLY 两个命令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 一个data携带两个cmd
struct {
uint32_t cmd_free ;
binder_uintptr_t buffer ;
uint32_t cmd_reply ;
struct binder_transaction_data td ;
} __attribute__ (( packed )) data ;
data . cmd_free = BC_FREE_BUFFER ;
data . buffer = td -> data . ptr . buffer ;
data . cmd_reply = BC_REPLY ;
data . td . target . ptr = 0 ;
data . td . cookie = 0 ;
data . td . code = CODE_REPLACE_AND_REPLY ;
data . td . flags = 0 ;
data . td . data_size = strlen ( result );
data . td . offsets_size = sizeof ( binder_size_t ) * 1 ;
data . td . data . ptr . buffer = ( binder_uintptr_t ) result ;
data . td . data . ptr . offsets = ( binder_uintptr_t ) offsets ;
int ret = binder_write ( bs , & data , sizeof ( data ));
先看第一个BC_FREE_BUFFER,既然要释放空间,那必然需要告诉binder需要释放哪个地址吧?
请问server端知道刚才给自己服务的 binder_buffer 的地址么? 很明显是不知道的,server端甚至不知道binder_buffer这个结构体的存在。
那server知道的是啥呢? 答曰,它只知道刚才读数据时的td->data.ptr.buffer和td->data.ptr.offsets,注意这两个都是userspace的地址;
那是否有必要buffer和offsets两个都发回去呢? 并不需要!
从上面5.2.2节创建和初始化binder_transaction_data的流程可知,td->data.ptr.buffer 其实就是对应的binder_buffer的user_data,我们可以回头回顾一下 第4节 主要数据结构 里最后的两张图所体现出来的vma、binder_buffer、pages之间的对应关系,就能知道我们可以从td->data.ptr.buffer检索出对应的binder_buffer,知道了binder_buffer就能知道其data_size和offset_size,也就知道了需要释放多大空间,然后根据对应关系也能知道对应的物理page何在。所以,上面紧跟在data.cmd_free后面的data.buffer中携带了server端刚才读取数据的td->data.ptr.buffer;
上面过程也解释了,为什么binder_buffer里面要存储其data_size和offset_size。 更广义地说,如果一个变量用来描述那些「可灵活分配和释放的空间」(例如binder_buffer,以及C中的指针),那么它必须不依赖其他变量就能知道自己的边界在哪里。 顺便问一个小问题:C语言中,malloc时需要指定size,但free时却不需要指明size,系统怎么知道要释放多大空间呢?有没有思考过?
最后一个问题:释放binder_buffer以及相关的page由server端还是client端完成呢? 答案是,由server端自己完成,因为最初分配空间时就是在server端分配的,映射的也是server端的vma。
server端陷入内核态后,会一路走到 binder_thread_write 函数,其中对 BC_FREE_BUFFER 的处理如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
static int binder_thread_write ( struct binder_proc * proc , struct binder_thread * thread ,
binder_uintptr_t write_buffer , size_t size , binder_size_t * consumed ) {
uint32_t cmd ;
void __user * buffer = ( void __user * )( uintptr_t ) write_buffer ;
void __user * ptr = buffer + * consumed ;
void __user * end = buffer + size ;
// 外层的while循环,是为了处理一个write写两个cmd的情况,
// 例如server通过一个ioctl写了一个包含 BC_FREE_BUFFER+ BC_REPLY的两个数据
while ( ptr < end ) {
if ( get_user ( cmd , ( uint32_t __user * ) ptr )) {
printk ( KERN_DEBUG "%s: binder_thread_write get_user ERROR \n " , current -> comm );
return - 1 ;
}
ptr += sizeof ( uint32_t );
switch ( cmd ) {
case BC_FREE_BUFFER : {
printk ( KERN_DEBUG "%s: binder_thread_write cmd=BC_FREE_BUFFER BEGIN { \n " , current -> comm );
binder_uintptr_t data_ptr ;
struct binder_buffer * buffer ;
if ( get_user ( data_ptr , ( binder_uintptr_t __user * ) ptr )) return - EFAULT ;
ptr += sizeof ( binder_uintptr_t );
printk ( KERN_DEBUG "%s: BC_FREE_BUFFER data_ptr=%llx \n " , current -> comm , ( u64 ) data_ptr );
// 找到待释放的 binder_buffer
buffer = binder_alloc_prepare_to_free ( & proc -> alloc , data_ptr );
if ( NULL == buffer ) {
pr_err ( "%s: binder_alloc_prepare_to_free cannot find binder_buffer with user_ptr=%llx \n " ,
current -> comm , ( u64 ) data_ptr );
return - 1 ;
}
printk ( KERN_DEBUG "%s: got binder_buffer(@ %llx user_data=%llx free=%d) \n " ,
current -> comm , ( u64 ) buffer , ( u64 ) buffer -> user_data , buffer -> free );
// 释放 binder_buffer
binder_alloc_free_buf ( & proc -> alloc , buffer );
printk ( KERN_DEBUG "%s: binder_alloc_free_buf() done! \n " , current -> comm );
printk ( KERN_DEBUG "%s: binder_thread_write cmd=BC_FREE_BUFFER END } \n " , current -> comm );
break ;
}
case BC_TRANSACTION :
case BC_REPLY : {
// 省略
}
}
* consumed = ptr - buffer ;
}
return 0 ;
}
首先,用get_user的方式从 write_buffer 中找到cmd后面跟随的地址 data_ptr,然后调用函数binder_alloc_prepare_to_free 检索对应于这个data_ptr的binder_buffer:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// 遍历alloc->buffers列表,找到 user_ptr 指针所对应的那个待释放的 binder_buffer
struct binder_buffer * binder_alloc_prepare_to_free ( struct binder_alloc * alloc , uintptr_t user_ptr ) {
struct binder_buffer * buffer ;
void __user * uptr = ( void __user * ) user_ptr ;
list_for_each_entry ( buffer , & alloc -> buffers , entry ) {
printk ( KERN_DEBUG
"%s: binder_alloc_prepare_to_free list_for_each_entry binder_buffer(@ %llx user_data=%llx free=%d) \n " ,
current -> comm , ( u64 ) buffer , ( u64 ) buffer -> user_data , buffer -> free );
if ( uptr == buffer -> user_data ) {
printk ( KERN_DEBUG "%s: binder_alloc_prepare_to_free: Find the buffer to free \n " , current -> comm );
return buffer ;
}
}
// 走完了list_for_each_entry,说明没有找到合适的,返回NULL
return NULL ;
}
这个逻辑不复杂,原生binder是遍历红黑树,我们这个例子是遍历list;有一个隐藏的细节希望大家能看到,这里传入的第一个参数是&proc->alloc,也就是说,是代表当前进程的binder_proc的binder_alloc 结构体,即server端自己的binder_alloc,而不是client端的;原因嘛,也很简单,因为当时分配内存时就是用的接收端的 binder_alloc(复习一下:用哪端的binder_alloc决定了从哪个binder_proc的binder_buffer列表中找空闲binder_buffer,也决定了最终alloc_page出来的物理内存映射到哪一端的vma里,详见第5.2.2节);
简单总结一下:binder_buffer的分配和释放、page的分配和释放、page插入vma和从vma移除,都发生在数据接收端!
找到对应的binder_buffer 后,就可以调用函数 binder_alloc_free_buf 来释放空间了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 释放指定参数所对应的 binder_buffer
// 原生binder的逻辑相对复杂,包含合并连续空闲空间、整个物理page都释放后才能释放物理页面等逻辑;
// 这里的做法非常简单,释放 binder_buffer 的同时也会释放其对应的物理页面;
void binder_alloc_free_buf ( struct binder_alloc * alloc , struct binder_buffer * buffer ) {
printk ( KERN_DEBUG "%s: %s(%d) binder_alloc_free_buf binder_buffer(@ %llx user_data=%llx free=%d) \n " ,
current -> comm , alloc -> name , alloc -> pid , ( u64 ) buffer , ( u64 ) buffer -> user_data , buffer -> free );
binder_update_page_range ( alloc , 0 ,
( void __user * ) PAGE_ALIGN (( uintptr_t ) buffer -> user_data ),
( void __user * ) PAGE_ALIGN (( uintptr_t ) buffer -> user_data + PAGE_SIZE ));
buffer -> data_size = 0 ;
buffer -> offsets_size = 0 ;
buffer -> pid = 0 ;
buffer -> free = 1 ;
}
好了,又到了老朋友 binder_update_page_range() 这里:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// 原生binder的这个函数逻辑比较复杂,原因是要处理各种情况,包括但不限于:
// binder_buffer跨内存页、binder_buffer大小小于内存页、binder_buffer起始地址与内存页不对齐、
// 分配/释放 binder_buffer 时是否需要分配/释放内存页 等等;
// 本例子里简化为仅仅分配或者释放一页内存(亦即参数end实际没有使用),所以要求参数start是一个pagesize的起点
static int binder_update_page_range ( struct binder_alloc * alloc , int allocate ,
void __user * start , void __user * end ) {
printk ( KERN_DEBUG "%s: binder_update_page_range: allocate=%d start=%llx end=%llx \n " ,
current -> comm , allocate , ( u64 ) start , ( u64 ) end );
void __user * page_addr = start ;
struct vm_area_struct * vma = alloc -> vma ;
size_t index = ( page_addr - alloc -> buffer ) / PAGE_SIZE ;
if ( end <= start ) {
printk ( KERN_DEBUG "%s: binder_update_page_range ERROR: end <= start \n " , current -> comm );
return 0 ;
}
printk ( KERN_DEBUG "%s: %s(%d) %s pages for userspace %llx--%llx \n " ,
current -> comm , alloc -> name , alloc -> pid , allocate ? "allocate" : "free" , ( u64 ) start , ( u64 ) end );
// 分配一页
if ( allocate == 1 ) {
// 省略
}
// 释放一页
else {
// 本例是每次分配和释放整个page,所以此时需要将整页从vma移除,否则下次使用相同的page_addr调用vm_insert_page时必现错误
zap_page_range ( vma , ( unsigned long ) page_addr , PAGE_SIZE ); // vm_insert_page 的逆操作
// 释放整个page,并更新alloc->pages 列表对应的指针值为NULL
struct page * page_ptr = alloc -> pages [ index ];
__free_page ( page_ptr ); // alloc_page 的逆操作
alloc -> pages [ index ] = NULL ;
printk ( KERN_DEBUG
"%s: free: alloc->pages[%ld] <--> kernel page_ptr %llx <--> userspace page_addr %llx \n " ,
current -> comm , index , ( u64 ) page_ptr , ( u64 ) page_addr );
return 0 ;
}
}
入参allocate为0表示释放一段空间,与分配时对应地,我们这里简化后需要做的是:
用入参alloc获知其alloc->vma和alloc->buffer,并计算出来对应的物理内存在alloc->pages列表的第几页;
调用zap_page_range 将一页内存从vma中移除,这是此前 vm_insert_page的逆操作;
调用 __free_page 释放alloc->pages列表中对应的物理内存页,并更新alloc->pages列表,这是alloc_page的逆操作;
(分配binder_buffer时,是先alloc_page,后vm_insert_page;释放时是反过来的,先zap_page_range,后__free_page,这很合理)
此刻,内存布局如下图所示:
用给定的userspace地址检索到binder_buffer后,此binder_buffer将会重新变成free=1的状态,图片正中央的一页物理内存会从vma中被移除并被释放,同时pages列表第0个元素将重新置NULL;
这个过程的日志如下:
1
2
3
4
5
6
7
8
9
10
11
[ 219.316925] server: binder_thread_write cmd=BC_FREE_BUFFER BEGIN {
[ 219.316926] server: BC_FREE_BUFFER data_ptr=7f64a7715000
[ 219.316927] server: binder_alloc_prepare_to_free list_for_each_entry binder_buffer(@ ffff8cb30bcbb000 user_data=7f64a7715000 free=0)
[ 219.316928] server: binder_alloc_prepare_to_free: Find the buffer to free
[ 219.316928] server: got binder_buffer(@ ffff8cb30bcbb000 user_data=7f64a7715000 free=0)
[ 219.316929] server: server(2539) binder_alloc_free_buf binder_buffer(@ ffff8cb30bcbb000 user_data=7f64a7715000 free=0)
[ 219.316931] server: binder_update_page_range: allocate=0 start=7f64a7715000 end=7f64a7716000
[ 219.316932] server: server(2539) free pages for userspace 7f64a7715000--7f64a7716000
[ 219.316940] server: free: alloc->pages[0] <--> kernel page_ptr ffffd09244695c80 <--> userspace page_addr 7f64a7715000
[ 219.316941] server: binder_alloc_free_buf() done!
[ 219.316941] server: binder_thread_write cmd=BC_FREE_BUFFER END }
从日志里可以看出来:
BC_FREE_BUFFER 确实完全在server进程(即刚刚的数据接收者)的内核态完成;
data_ptr的值7f64a7715000,binder_buffer的地址ffff8cb30bcbb000,都是与此前找到的空闲buffer是一致的。可见我们确实释放了刚才使用的binder_buffer和page;
5.6 BC_REPLY
从BC_REPLY开始,binder通信将会走到其后半程,其实这个过程和前半程是几乎一样的,只是方向相反罢了。所以,后续我们就不再逐行分析和画图了。
先看一下相关日志:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
[ 219.316942] server: binder_thread_write cmd=BC_REPLY BEGIN {
[ 219.316943] server: binder_transaction() BEGIN {
[ 219.316943] server --> client BC_REPLY data.ptr.buffer=55c4e771f8b0 data.ptr.offsets=7ffff6ce92d8 data_size=12 offsets_size=8
[ 219.316946] server: binder_alloc_new_buf list_for_each_entry binder_buffer(@ ffff8caf446fd0c0 user_data=7fae812f3000 free=1)
[ 219.316947] server: binder_alloc_new_buf: GOT free buffer
[ 219.316947] server: binder_update_page_range: allocate=1 start=7fae812f3000 end=7fae812f4000
[ 219.316948] server: client(2541) allocate pages for userspace 7fae812f3000--7fae812f4000
[ 219.316949] server: allocate: alloc->pages[0] <--> kernel page_ptr=ffffd09244695c80 <--> userspace page_addr=7fae812f3000
[ 219.316951] server: vm_insert_page(ffff8caf6449a688, 7fae812f3000, ffffd09244695c80)
[ 219.316951] client: binder_thread_read BINDER_WORK_TRANSACTION_COMPLETE BEGIN {
[ 219.316952] client: binder_thread_read put_user cmd=BR_TRANSACTION_COMPLETE
[ 219.316953] client: binder_thread_read BINDER_WORK_TRANSACTION_COMPLETE END }
[ 219.316954] server: binder_alloc_get_page: alloc->buffer=7fae812f3000 binder_buffer(@ ffff8caf446fd0c0 user_data=7fae812f3000 free=0) buffer_offset=0
[ 219.316955] server: binder_alloc_get_page: index=0 pgoff=0 page=ffffd09244695c80
[ 219.316956] server: binder_alloc_copy_user_to_buffer: kmap(ffffd09244695c80) got kernel virtual addr ffff8caf5a572000
[ 219.316957] server: binder_alloc_copy_user_to_buffer: copy_from_user(ffff8caf5a572000, 55c4e771f8b0, 12)
[ 219.316958] server: binder_alloc_get_page: alloc->buffer=7fae812f3000 binder_buffer(@ ffff8caf446fd0c0 user_data=7fae812f3000 free=0) buffer_offset=10
[ 219.316959] server: binder_alloc_get_page: index=0 pgoff=10 page=ffffd09244695c80
[ 219.316960] server: binder_alloc_copy_user_to_buffer: kmap(ffffd09244695c80) got kernel virtual addr ffff8caf5a572000
[ 219.316961] server: binder_alloc_copy_user_to_buffer: copy_from_user(ffff8caf5a572010, 7ffff6ce92d8, 8)
[ 219.316962] server: --> client BINDER_WORK_TRANSACTION (code=1 buffer=ffff8caf446fd0c0 data_size=12 offsets_size=8)
[ 219.316964] server: --> server BINDER_WORK_TRANSACTION_COMPLETE
[ 219.316965] server: binder_transaction() END }
[ 219.316965] server: binder_thread_write cmd=BC_REPLY END }
[ 219.317265] server: binder_thread_read BINDER_WORK_TRANSACTION_COMPLETE BEGIN {
[ 219.317266] server: binder_thread_read put_user cmd=BR_TRANSACTION_COMPLETE
[ 219.317267] server: binder_thread_read BINDER_WORK_TRANSACTION_COMPLETE END }
server进程写第二条命令 BC_REPLY,会执行到binder_transaction()函数;
因为接收者是client,所以需要分配binder_buffer 和 物理页面,并关联到client进程的vma,然后用两次 copy_from_user 将数据写入 client的vma对应的页面;检查我们找到的binder_buffer的内存地址=ffff8caf446fd0c0 和 user_data=7fae812f3000 都能跟最初 open和mmap时的日志对应上;7fae812f3000是client进程的vma的首地址;整个过程中,binder_alloc_new_buf、binder_update_page_range、alloc_page、vm_insert_page、binder_alloc_get_page、binder_alloc_copy_user_to_buffer、kmap等等一系列的函数在 第5.2.3节~第5.2.4节 都已经讲过了;
然后是work的流转,即发一个 type=BINDER_WORK_TRANSACTION的work给client进程,发一个type = BINDER_WORK_TRANSACTION_COMPLETE 的work给server进程;
在这期间client 端收到了 BINDER_WORK_TRANSACTION_COMPLETE,即驱动告知它 BC_TRANSACTION 处理完毕;随后server端很快也读到了发给自己的 BINDER_WORK_TRANSACTION_COMPLETE 工作项;(complete的日志,此前第5.4节已经讲了;这里可以看到client的日志和server的日志交错打出来,也说明二者确实是并发运行的)
上面日志里有一个有趣的事情是:这次执行alloc_page后,获得的物理内存页 kernel page_ptr=ffffd09244695c80,正好和 BC_TRANSACTION 的 binder_transaction() 时分配的是同一个,也就是说,内核层面其实也在按照LRU算法来分配物理页;
5.7 BR_REPLY
然后是client端收到BR_REPLY的过程,逻辑上和 BR_TRANSACTION 几乎是一样的;
client 进程通过ioctl读 的方式进入内核态,摘取 type=BINDER_WORK_TRANSACTION 的work,获取到 binder_transaction_data;
用 put_user 和 copy_to_user 将 BR_REPLY 和 binder_transaction_data 传输给client进程的用户空间;
回到用户空间后,client处理收到的binder_transaction_data;
这段时间的日志:
1
2
3
4
5
[ 219.317638] client: binder_thread_read BINDER_WORK_TRANSACTION BEGIN {
[ 219.317640] client: binder_transaction(code=1, data_size=12, offsets_size=8 buffer->user_data=7fae812f3000)
[ 219.317642] client: put_user: cmd=BR_REPLY
[ 219.317643] client: copy_to_user: binder_transaction_data (code=1 data_size=12 offsets_size=8 data.ptr.buffer=7fae812f3000 data.ptr.offsets=7fae812f3010)
[ 219.317645] client: binder_thread_read BINDER_WORK_TRANSACTION END }
5.8 BC_FREE_BUFFER
client的用户态处理完毕reply数据后,会同样用 ioctl写 的方式发出一个 BC_FREE_BUFFER 命令,携带刚才收reply数据的userspace地址 7fae812f3000,陷入用户态后,执行跟 第5.5节 一样的逻辑;
1
2
3
4
5
6
7
8
9
10
11
[ 219.317699] client: binder_thread_write cmd=BC_FREE_BUFFER BEGIN {
[ 219.317700] client: BC_FREE_BUFFER data_ptr=7fae812f3000
[ 219.317701] client: binder_alloc_prepare_to_free list_for_each_entry binder_buffer(@ ffff8caf446fd0c0 user_data=7fae812f3000 free=0)
[ 219.317702] client: binder_alloc_prepare_to_free: Find the buffer to free
[ 219.317702] client: got binder_buffer(@ ffff8caf446fd0c0 user_data=7fae812f3000 free=0)
[ 219.317703] client: client(2541) binder_alloc_free_buf binder_buffer(@ ffff8caf446fd0c0 user_data=7fae812f3000 free=0)
[ 219.317704] client: binder_update_page_range: allocate=0 start=7fae812f3000 end=7fae812f4000
[ 219.317705] client: client(2541) free pages for userspace 7fae812f3000--7fae812f4000
[ 219.317712] client: free: alloc->pages[0] <--> kernel page_ptr ffffd09244695c80 <--> userspace page_addr 7fae812f3000
[ 219.317713] client: binder_alloc_free_buf() done!
[ 219.317713] client: binder_thread_write cmd=BC_FREE_BUFFER END }
好了,整个流程完毕!
希望能帮到大家。祝大家平安喜乐!
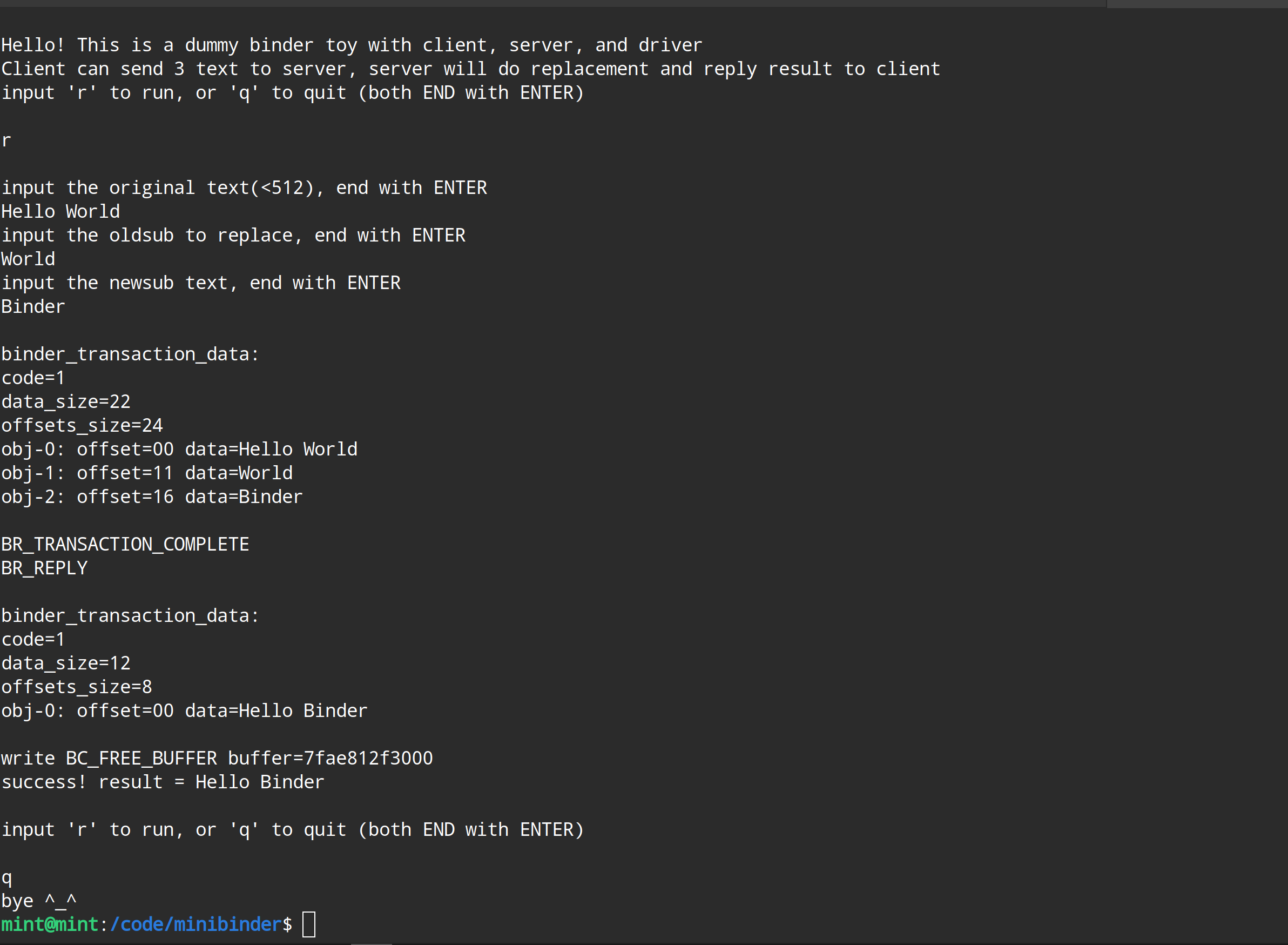
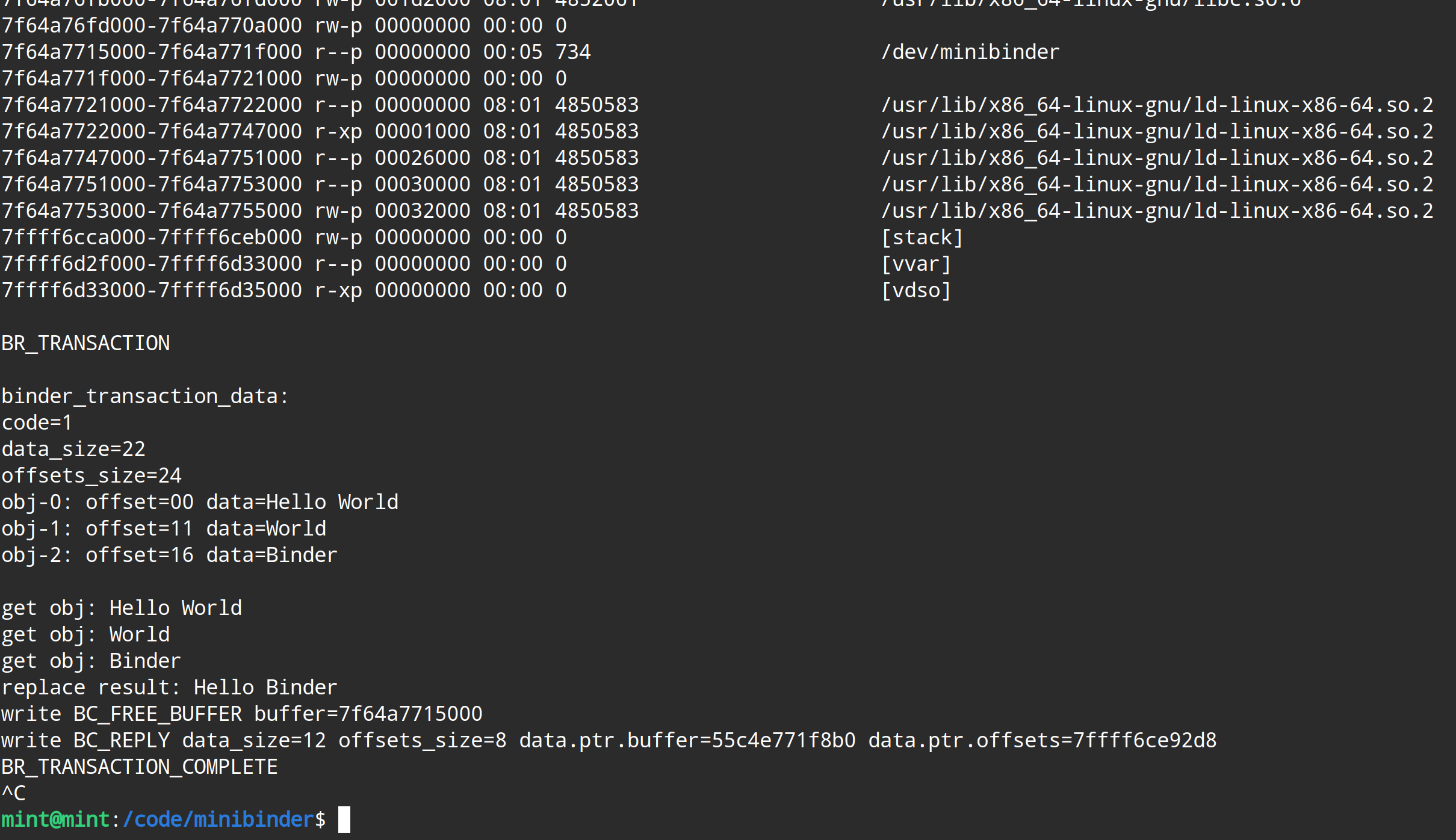
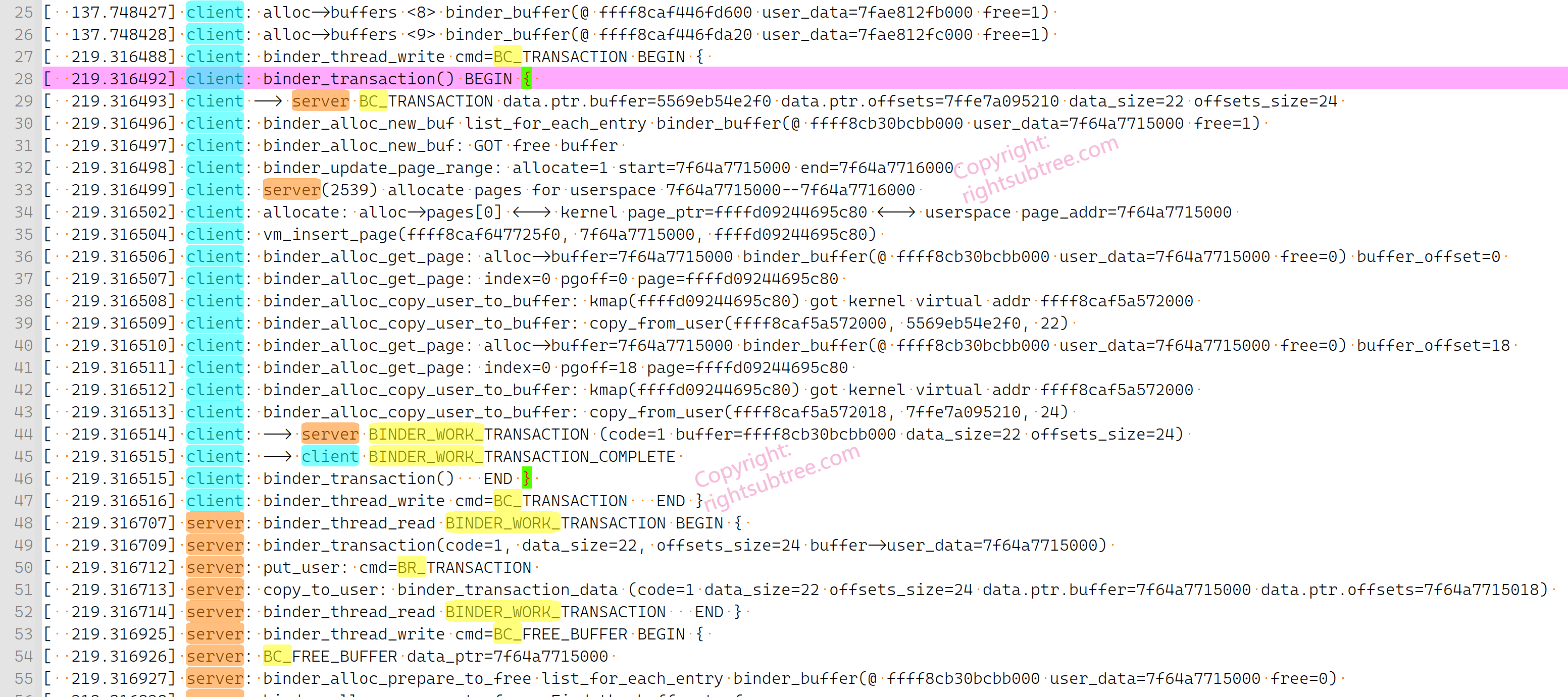
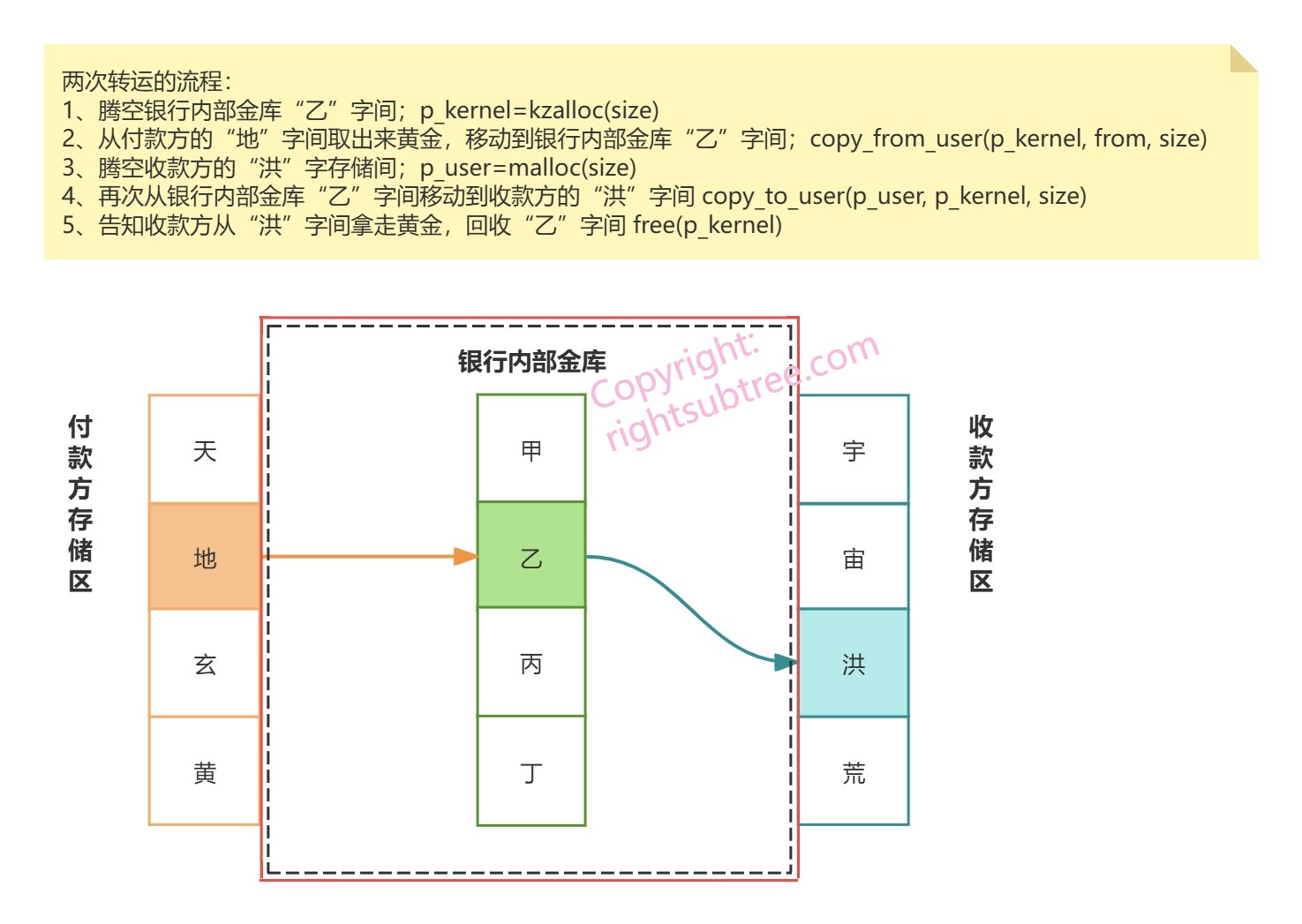
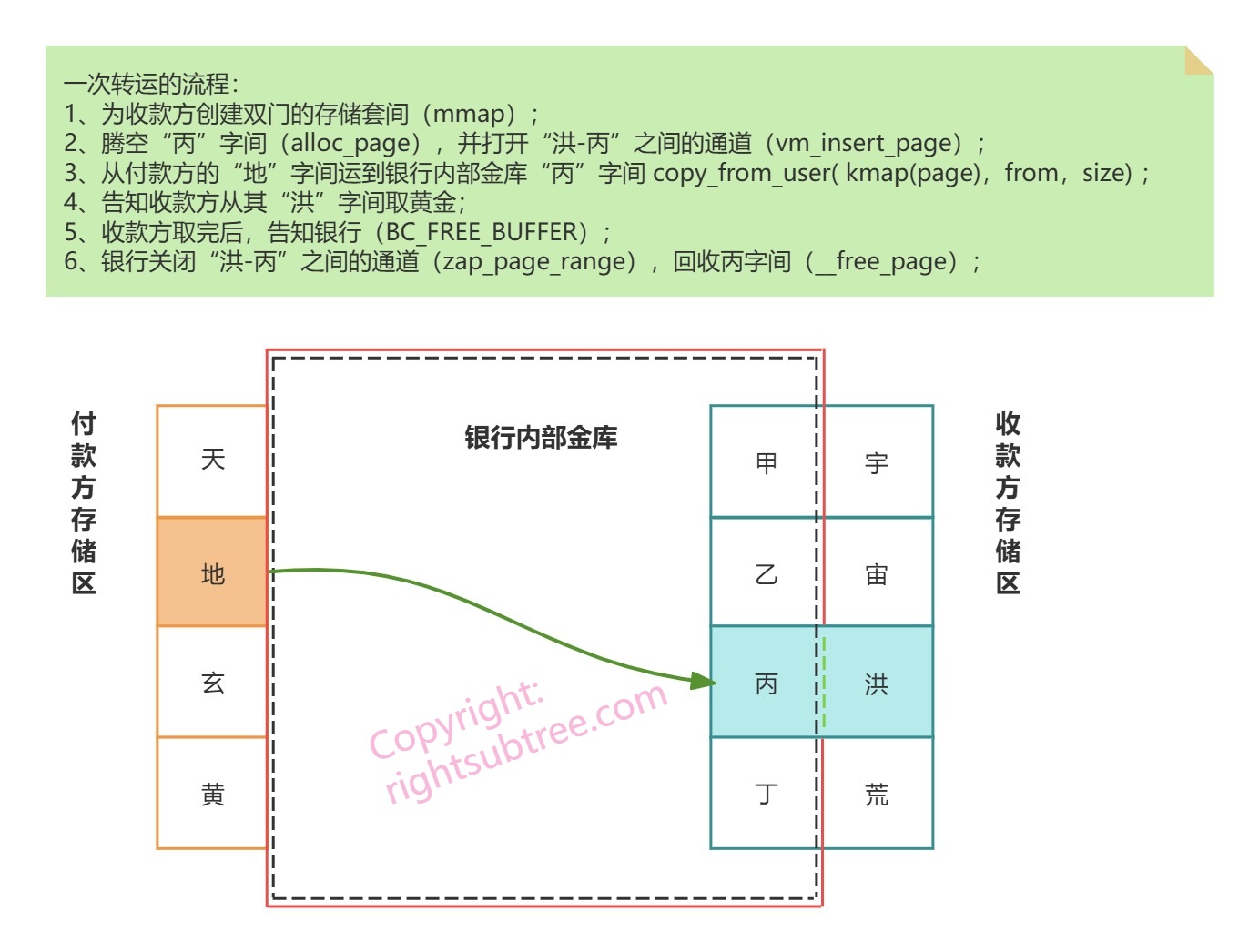
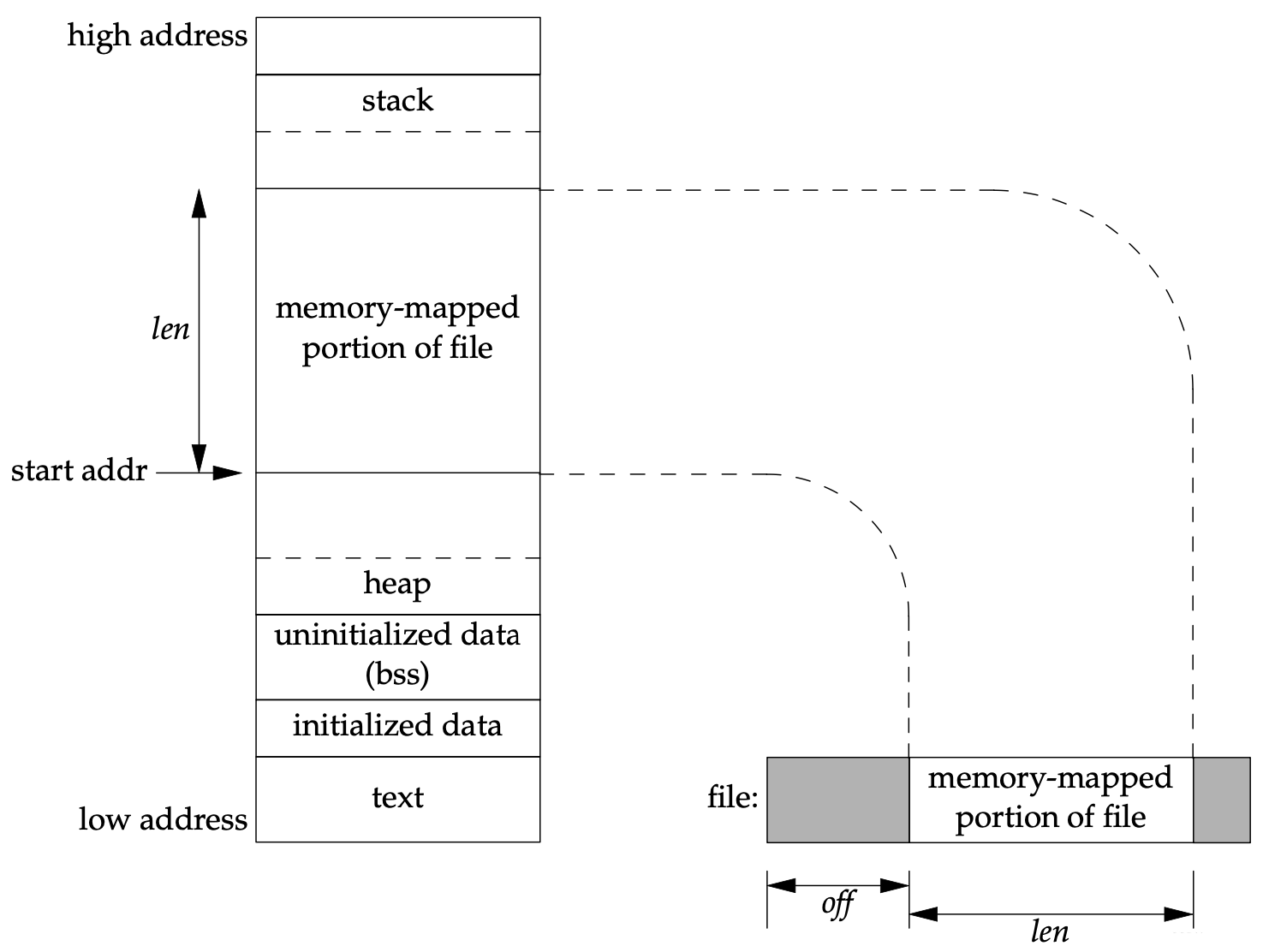
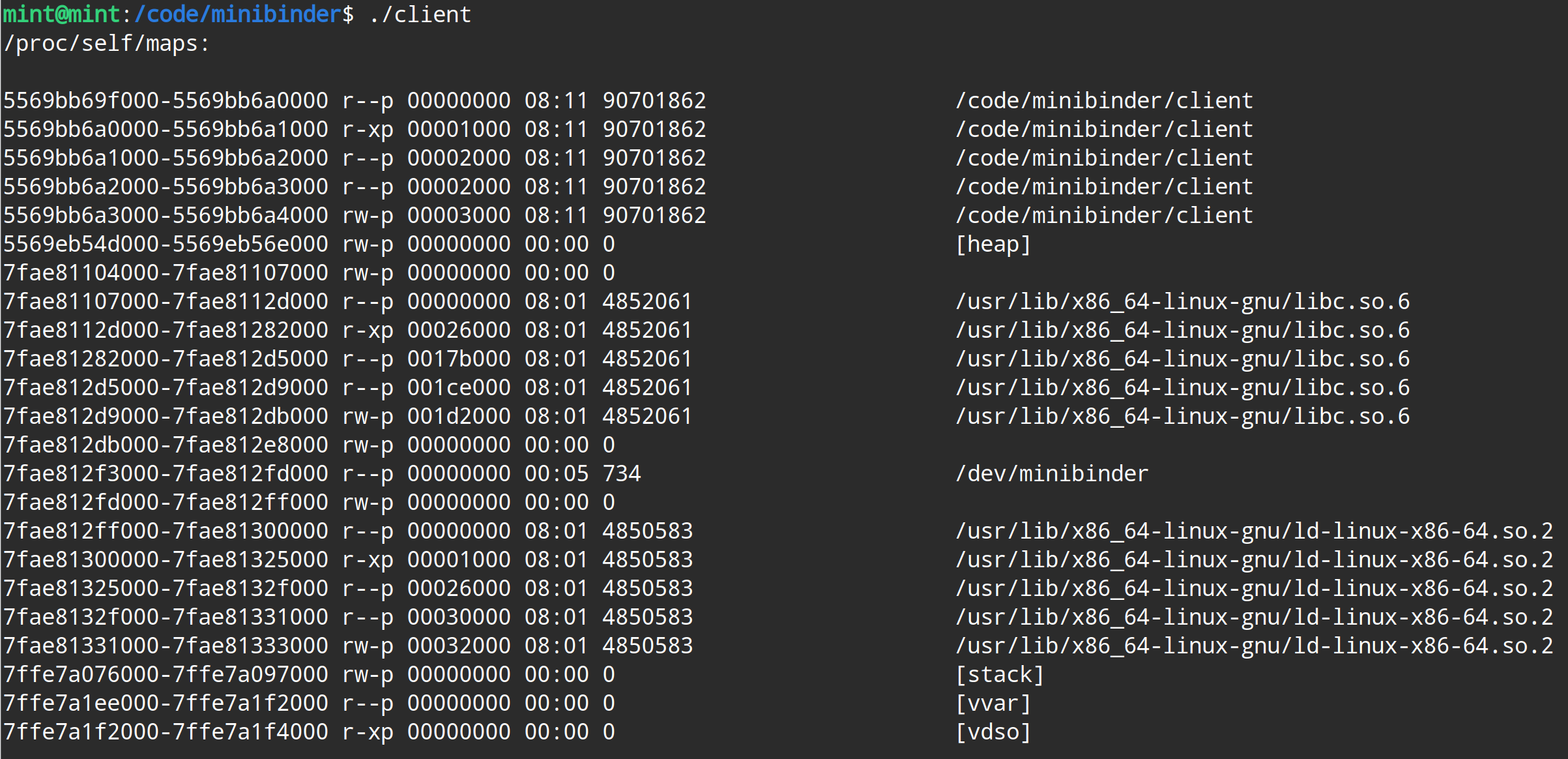
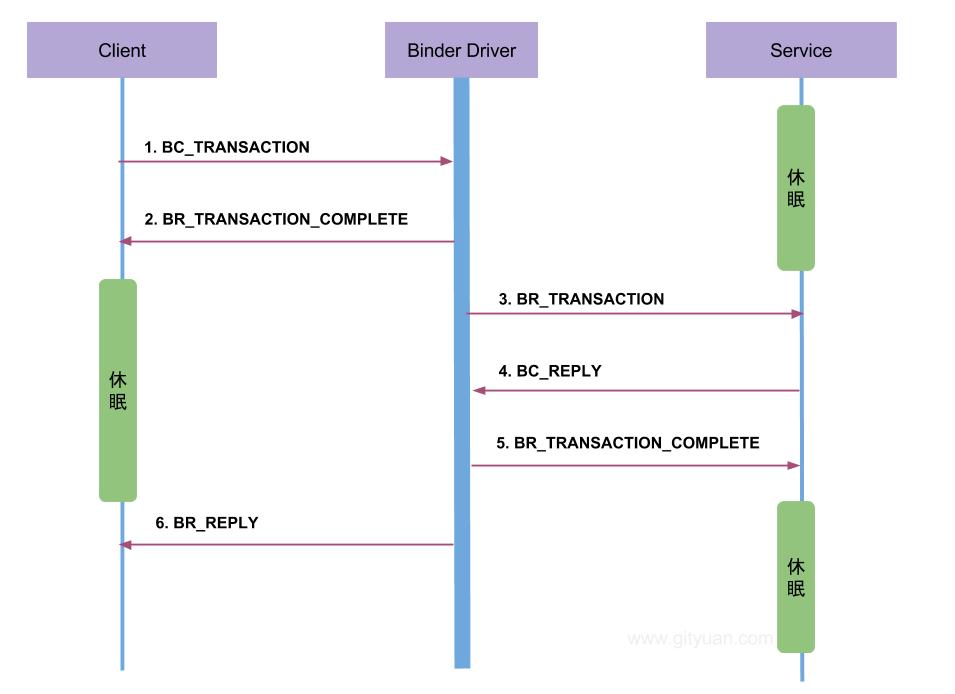
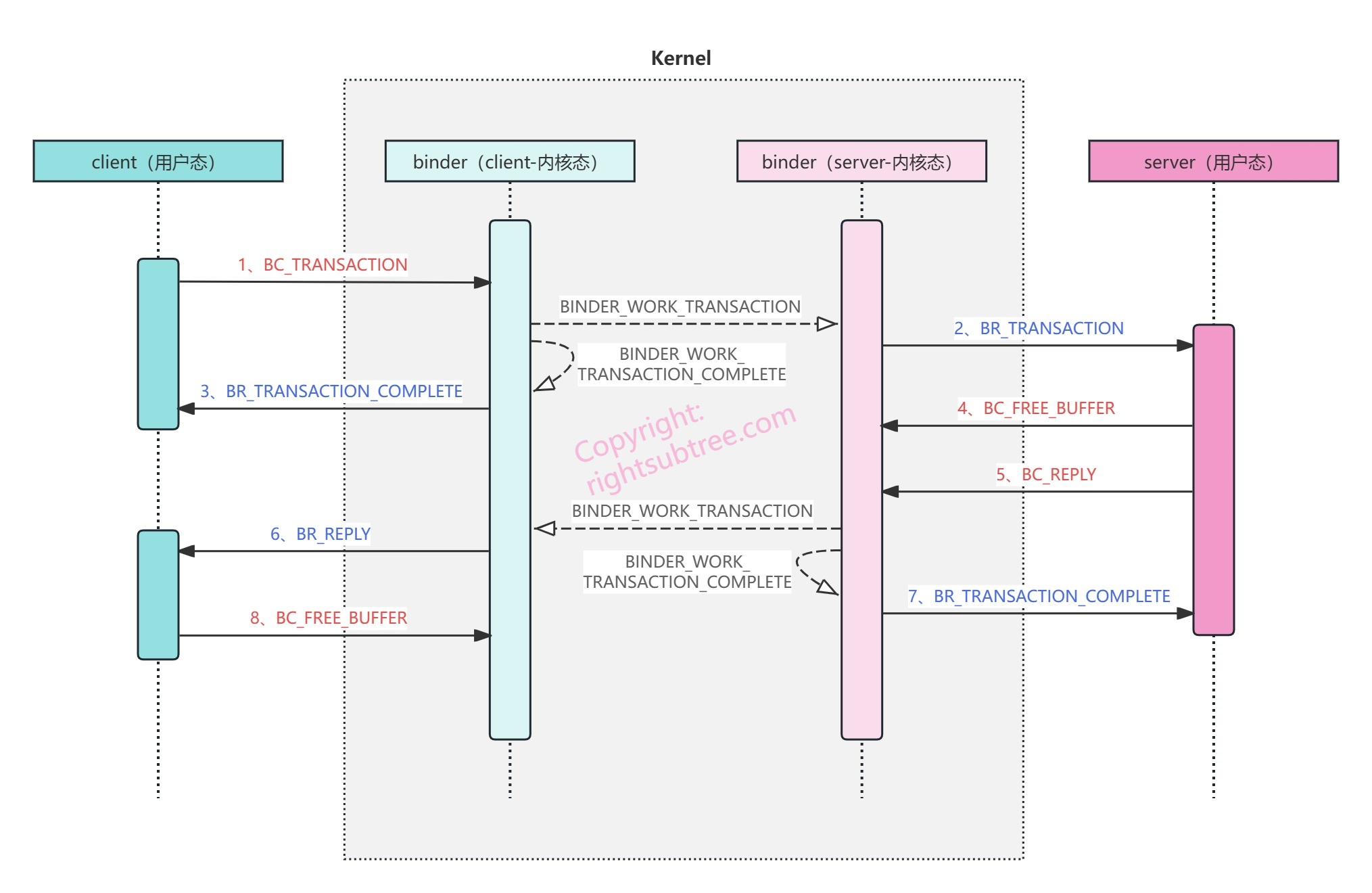
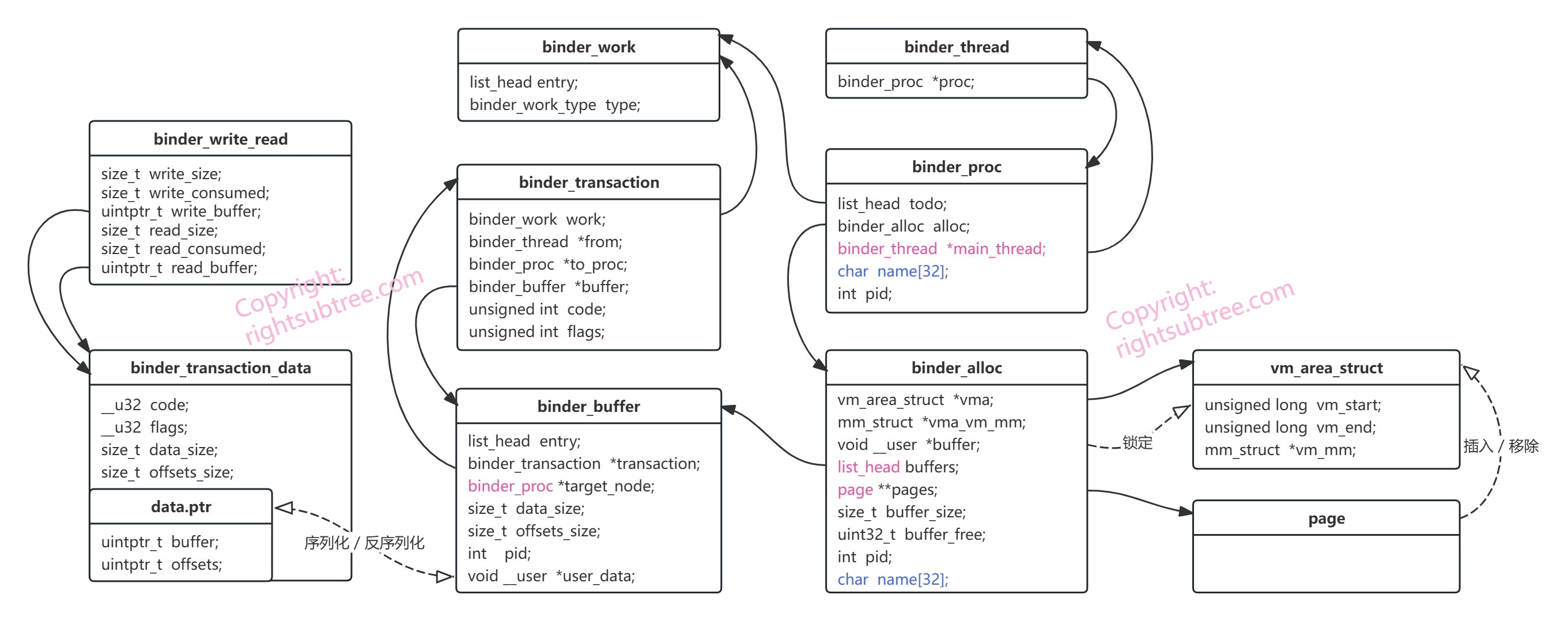

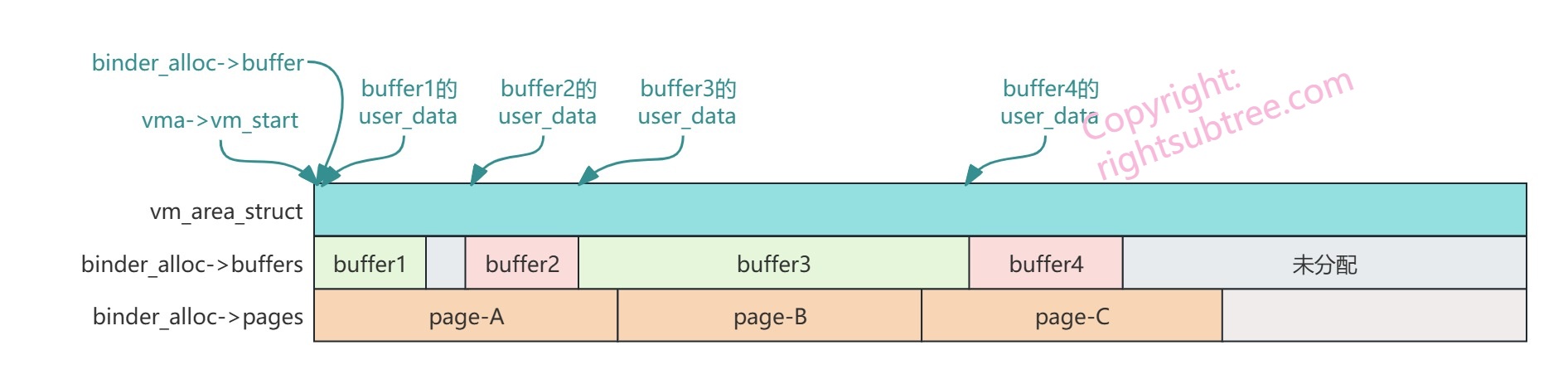
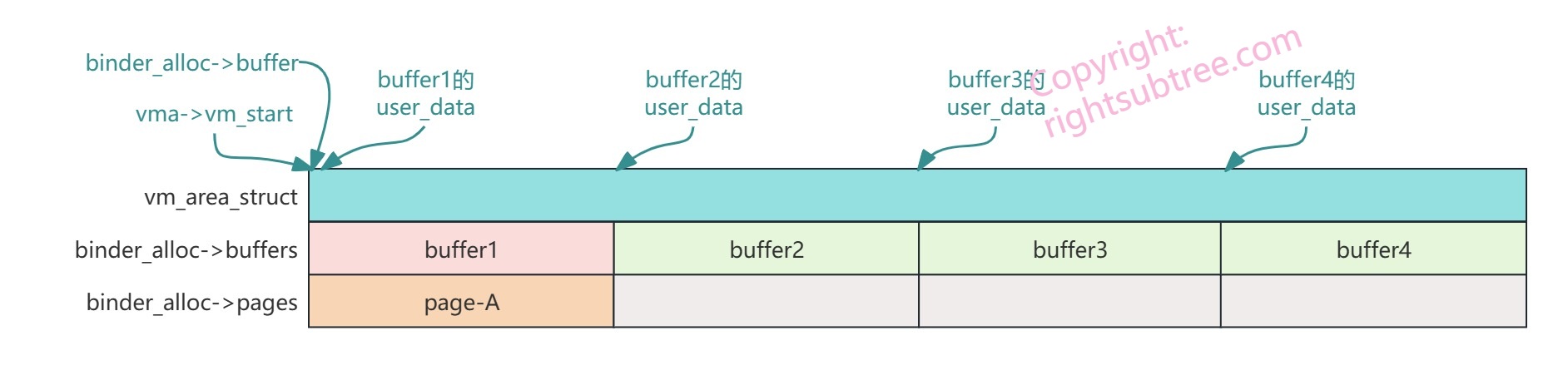
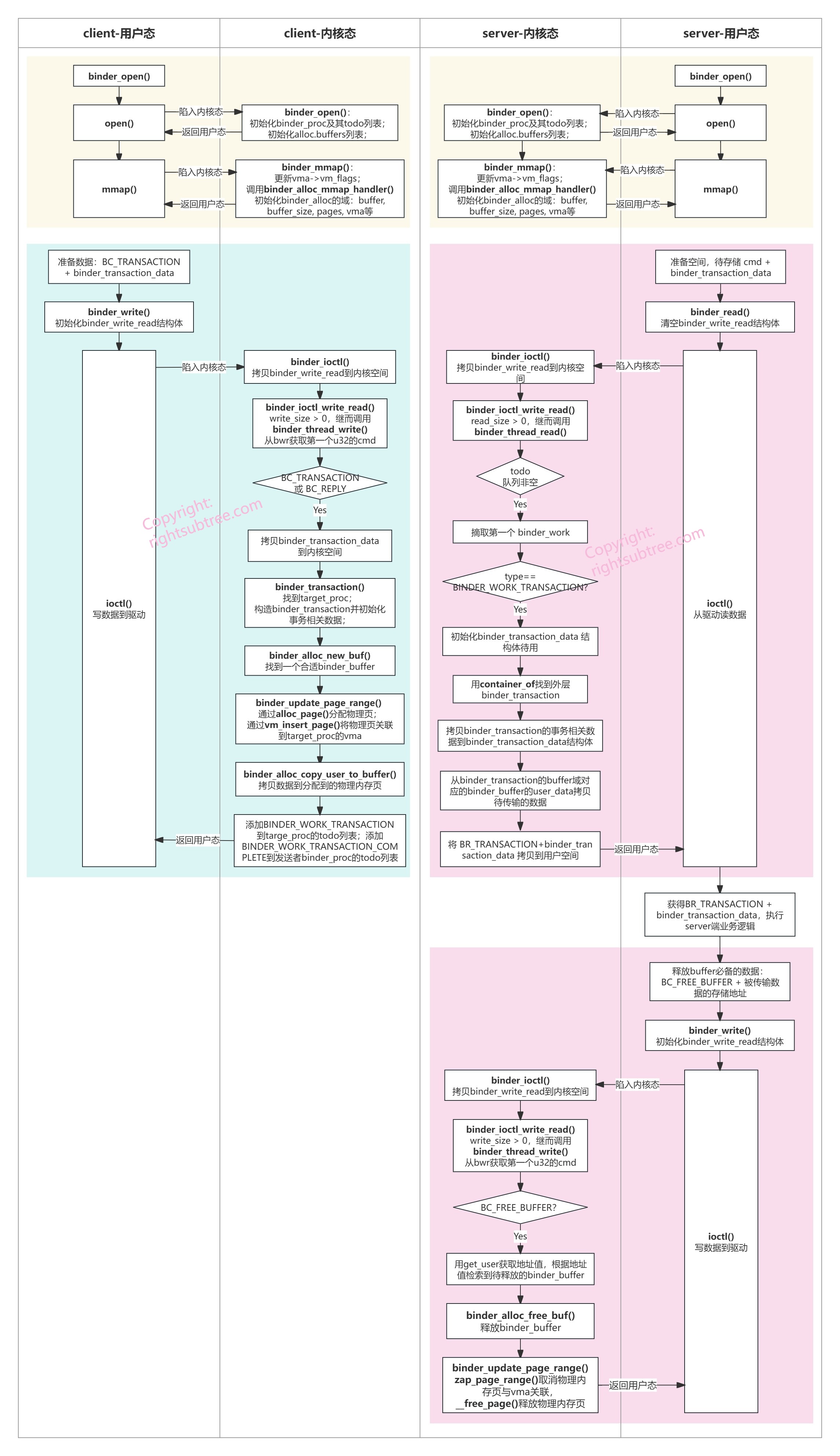
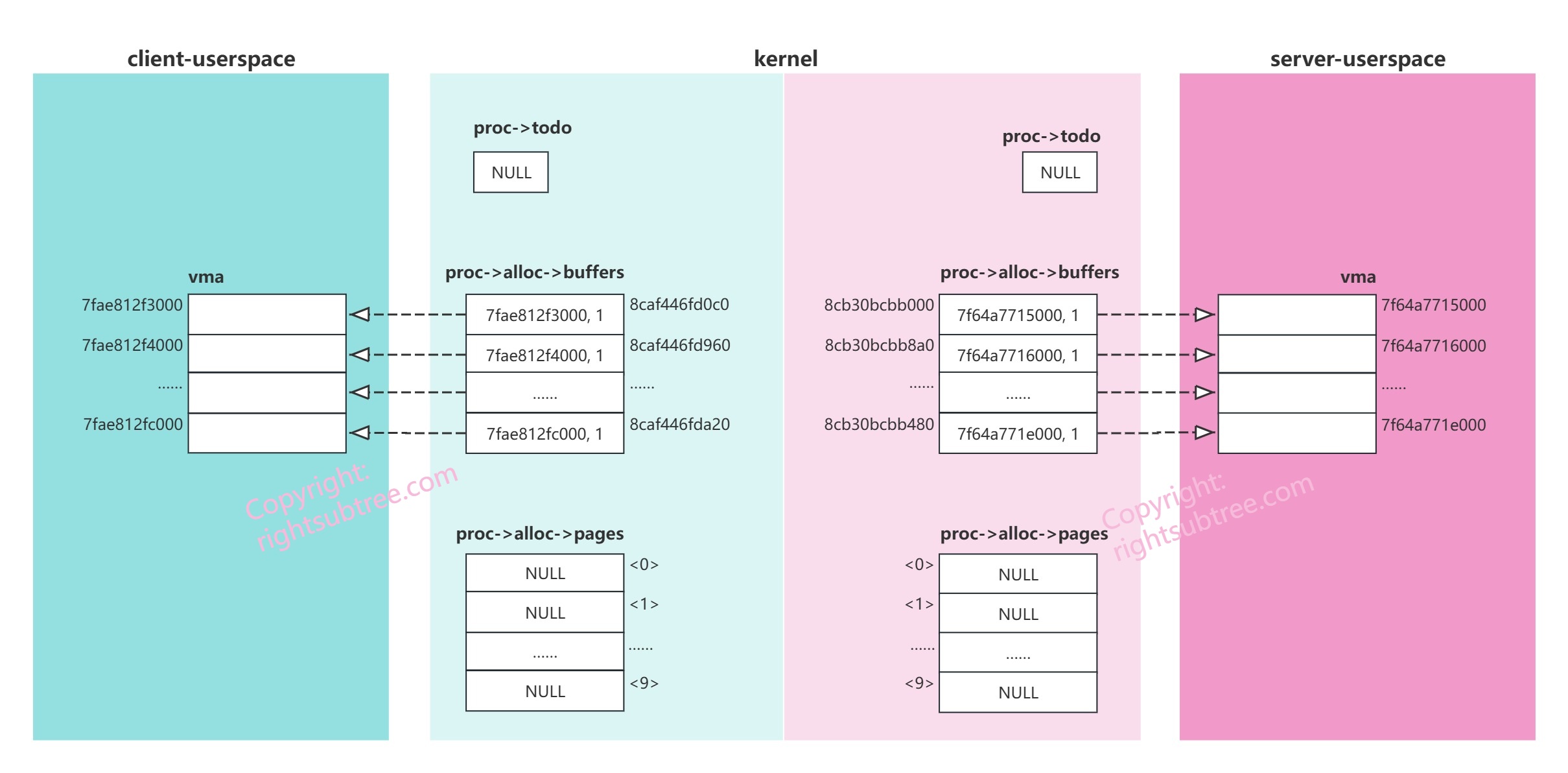
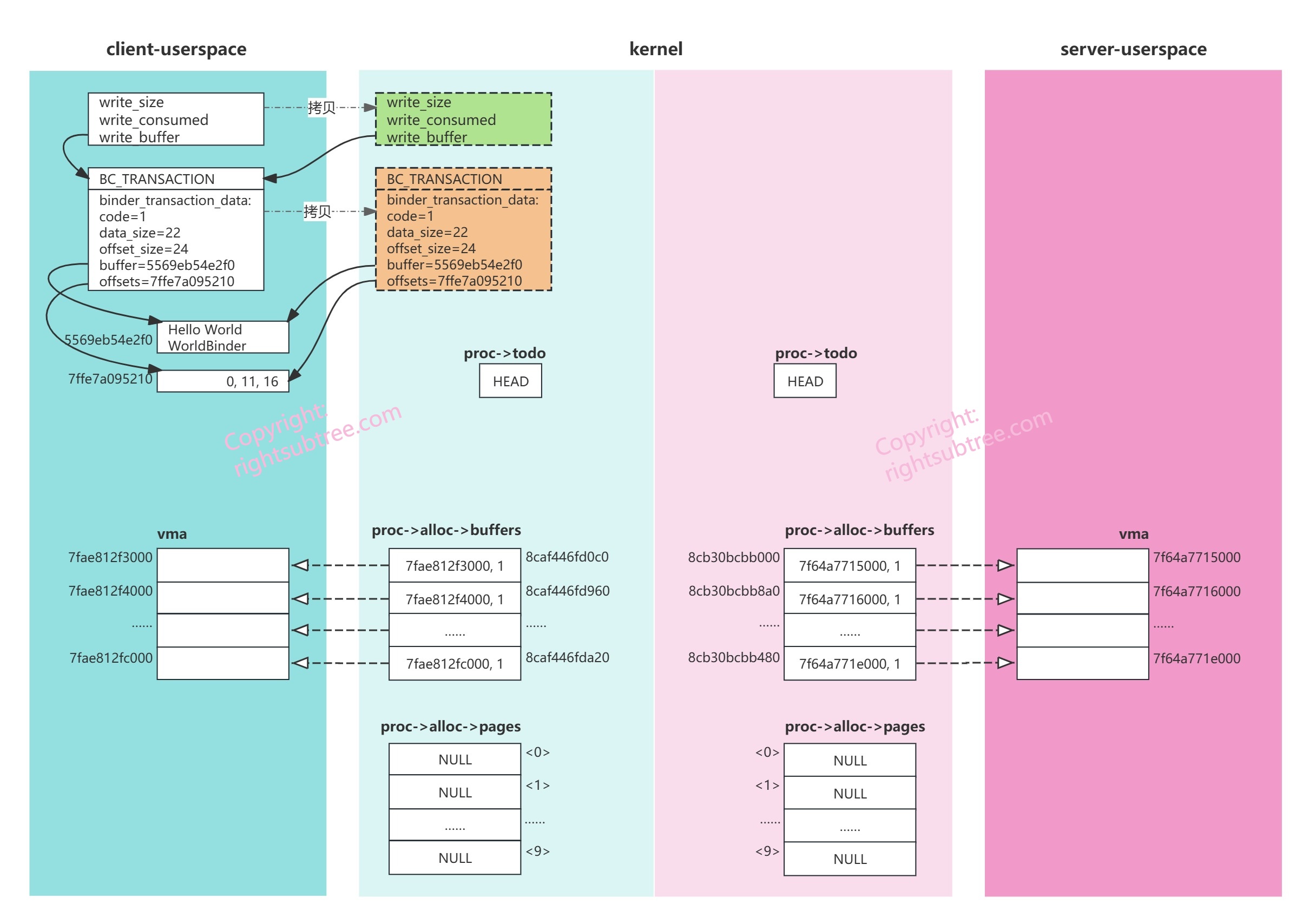
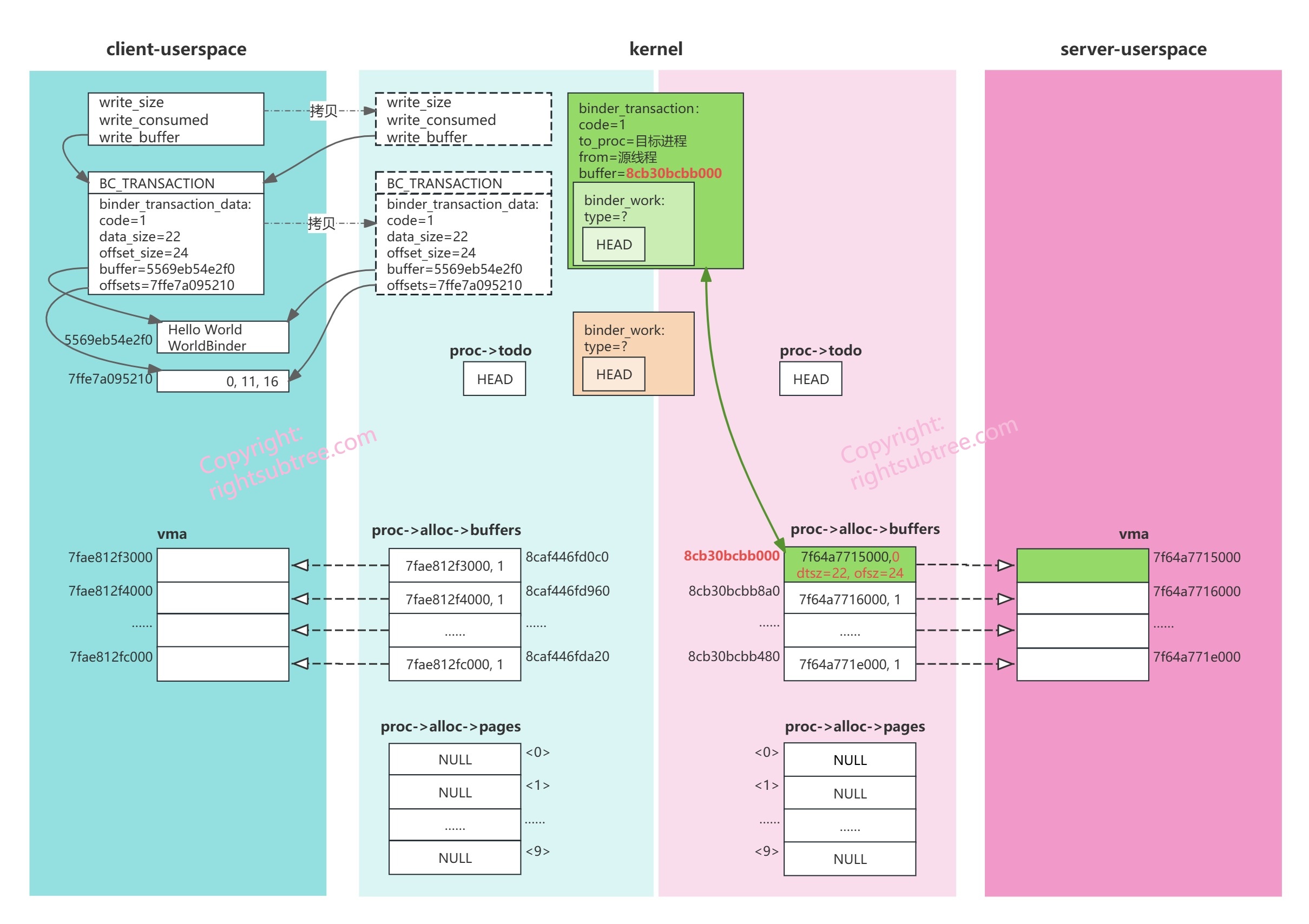
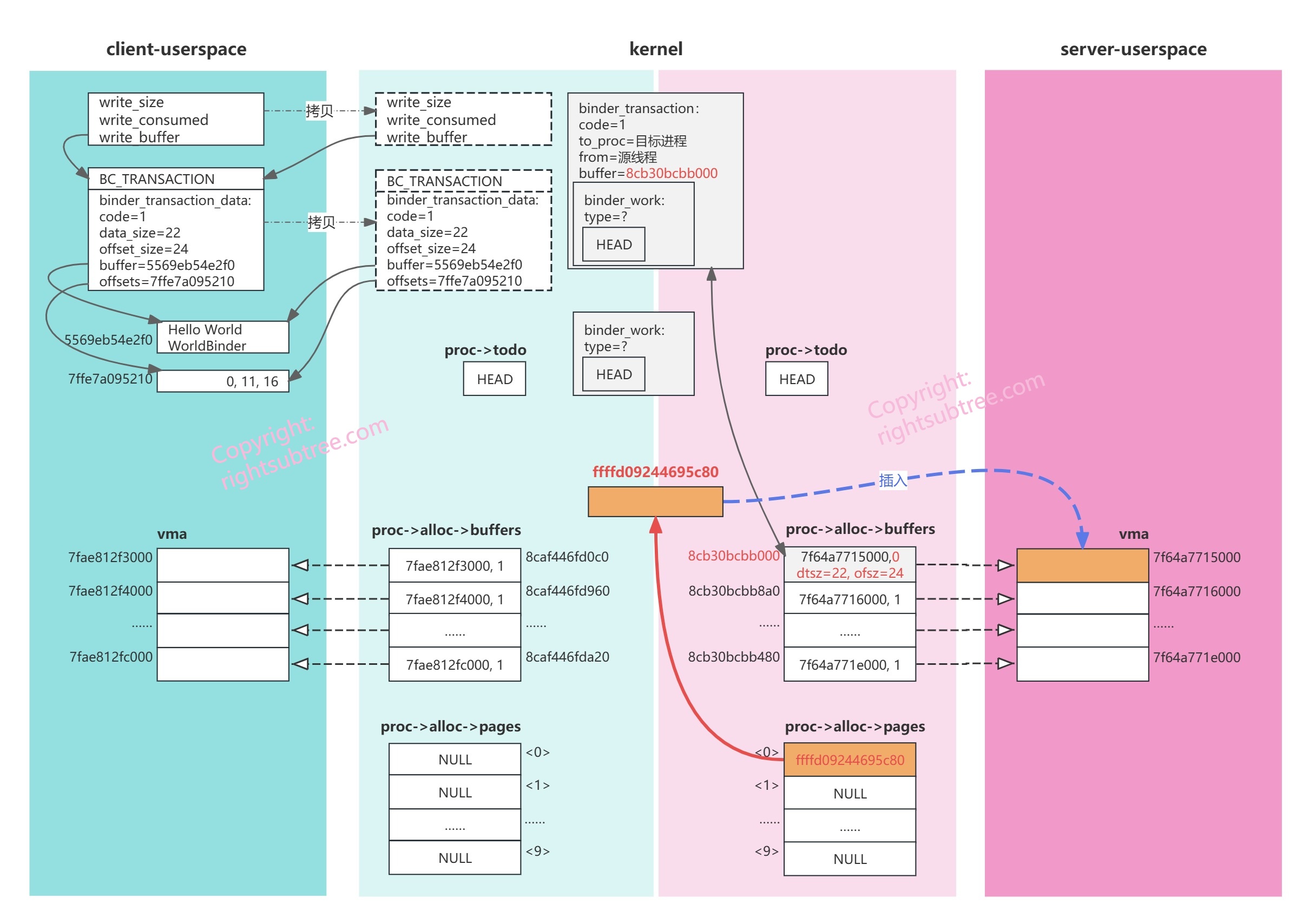

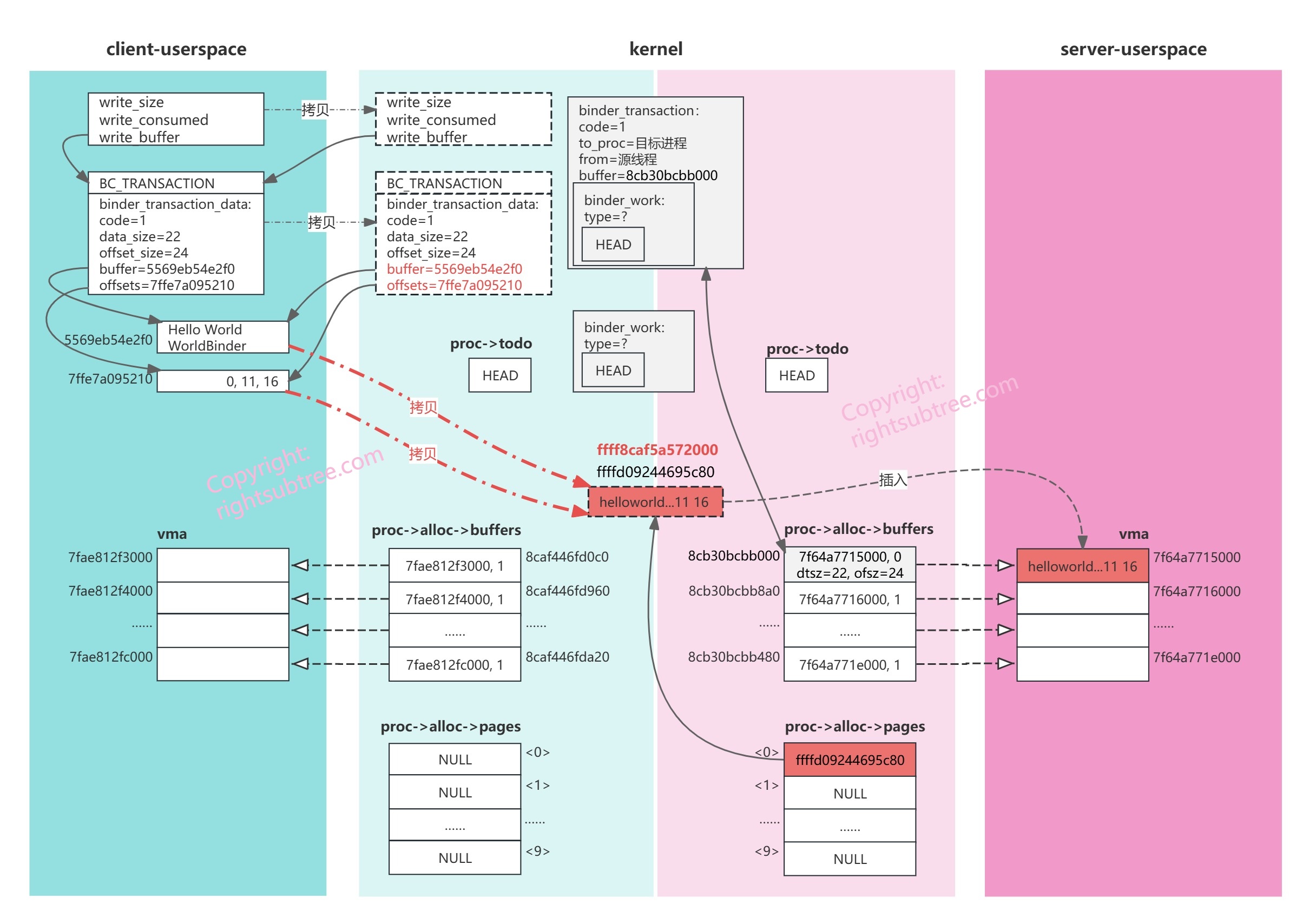
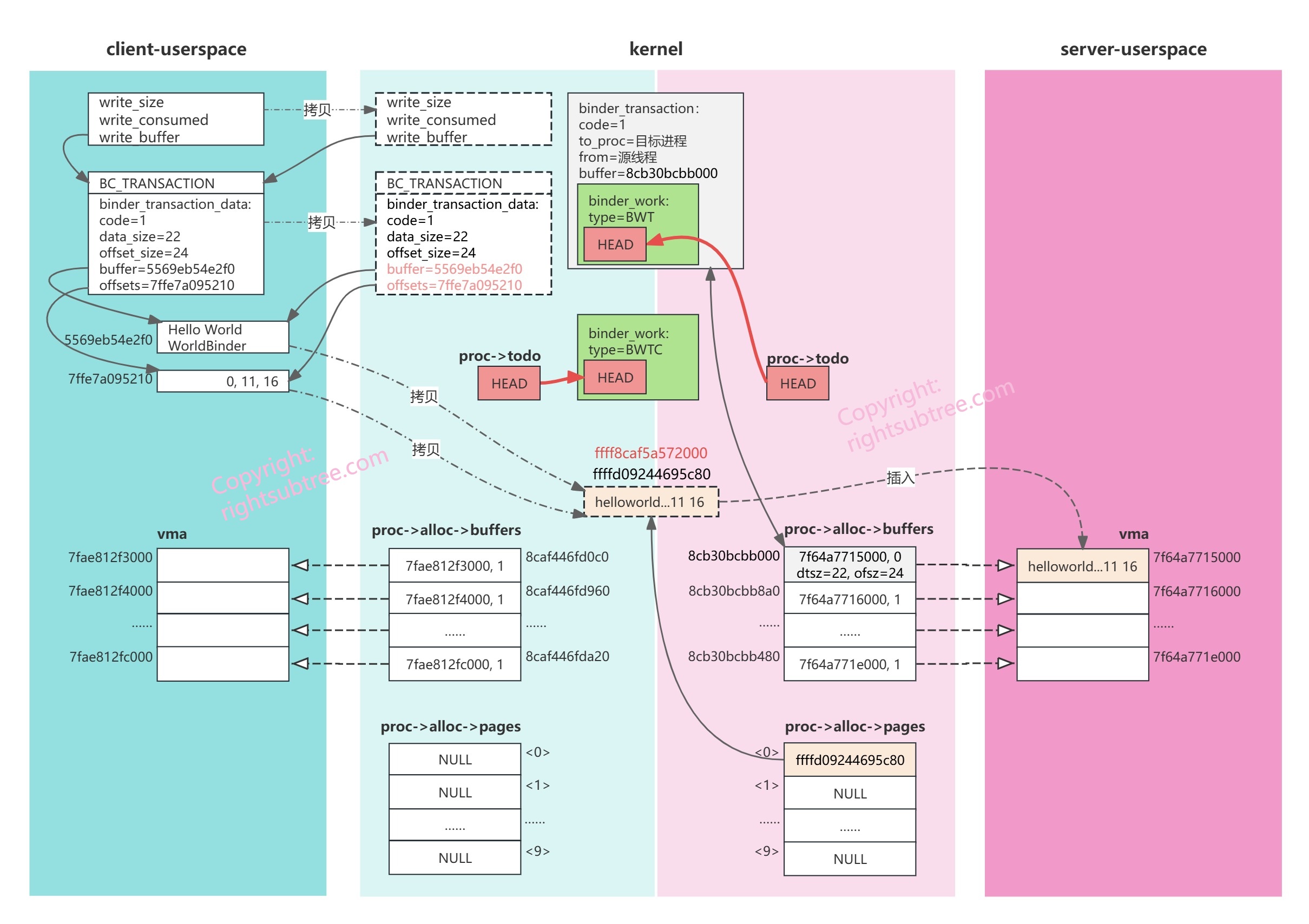
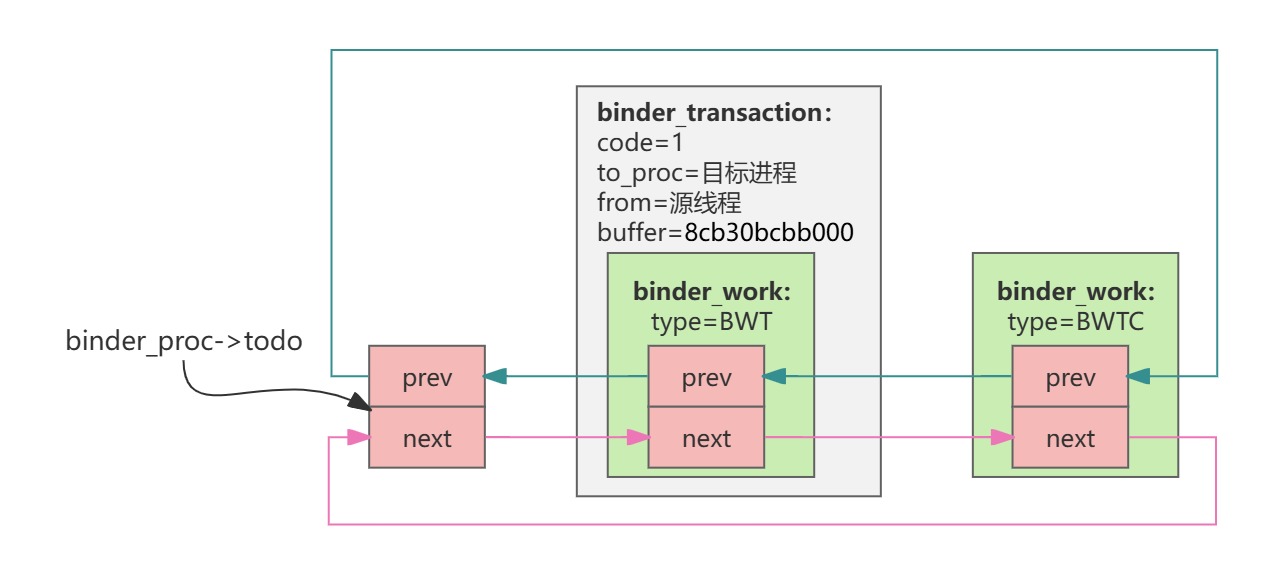
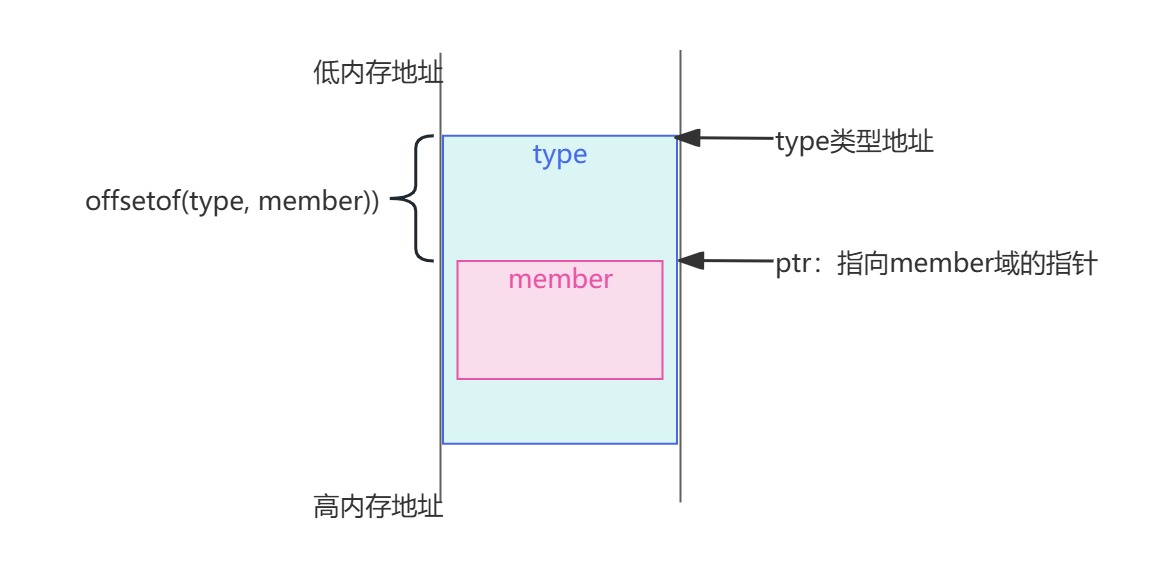
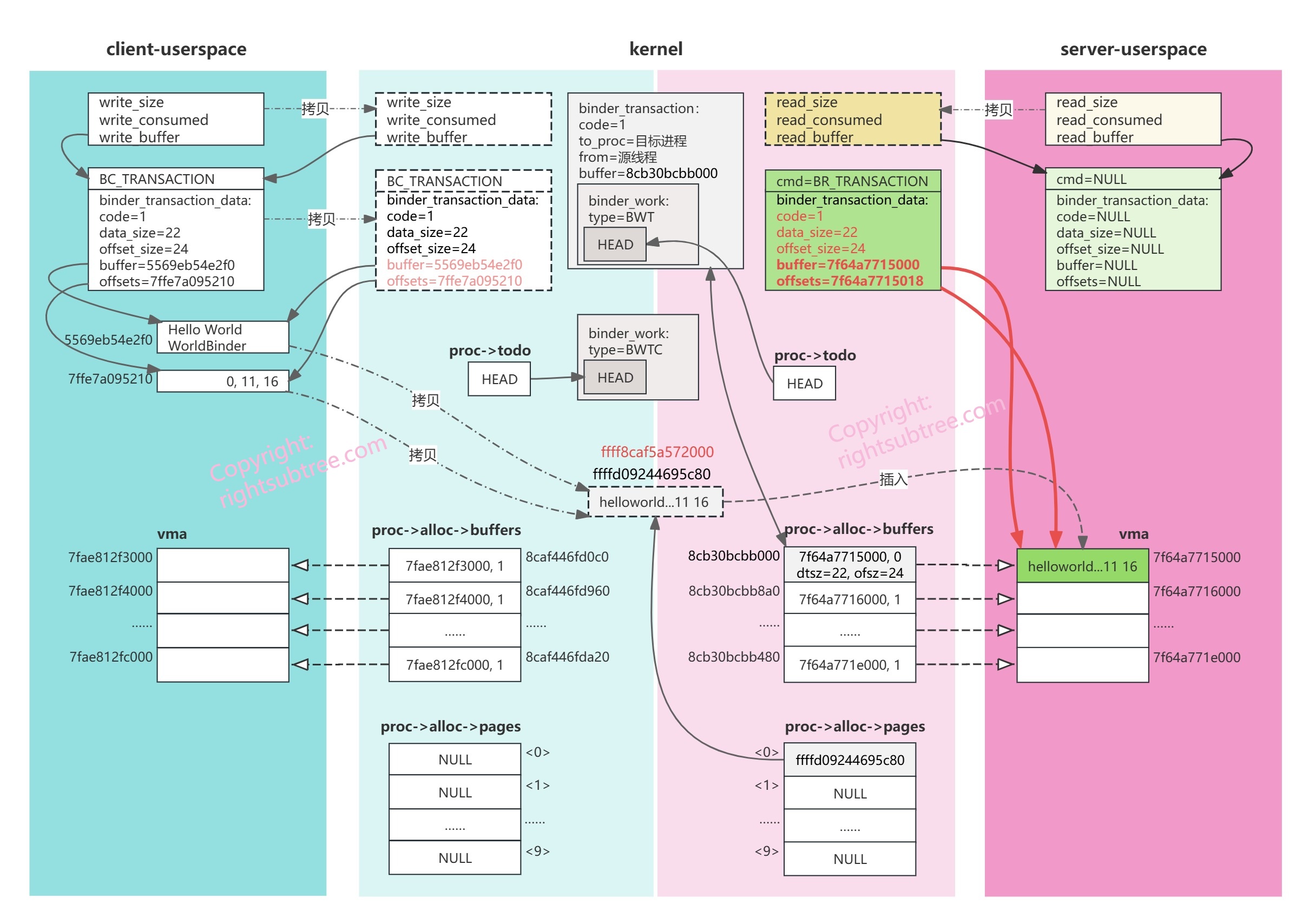
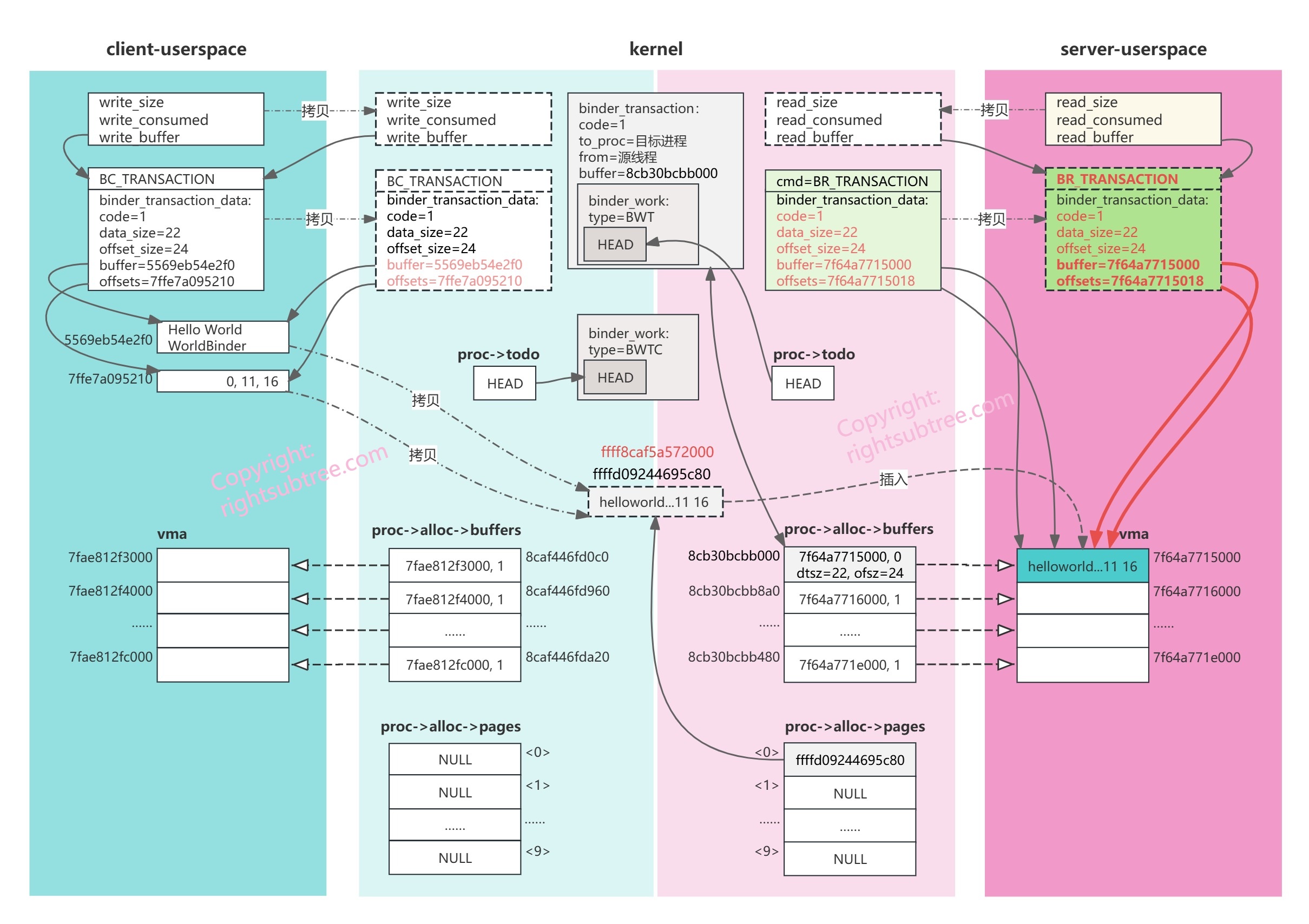
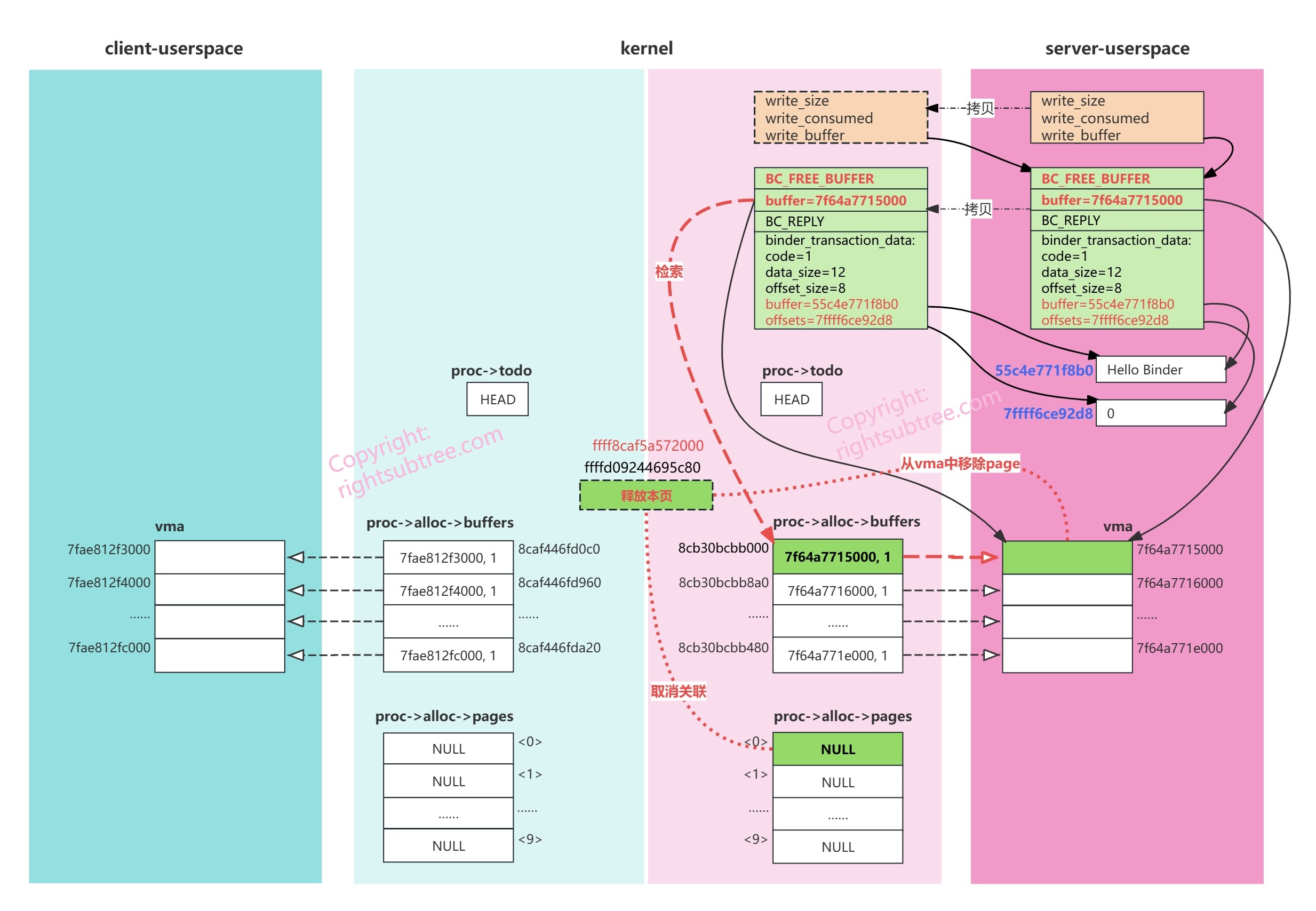
 支付宝
支付宝 微信
微信